AI to świetny analityk – ale z pamięcią zatrzymaną w czasie. Potrafi łączyć fakty, wyciągać wnioski i pisać jak ekspert. Problem w tym, że jego „świat” kończy się w określonym momencie. Dla biznesu oznacza to jedno: bez dostępu do aktualnych danych nawet najlepszy model może prowadzić do błędnych decyzji. Dlatego prawdziwa wartość AI nie leży dziś w samej technologii, ale w tym, jak podłączysz ją do rzeczywistości.
1. Czym jest knowledge cutoff i dlaczego istnieje
Knowledge cutoff to graniczna data, po której model nie ma gwarantowanej (a często żadnej) „wrodzonej” wiedzy, bo nie „wczytywał” nowszych danych podczas treningu. Dostawcy zwykle opisują to wprost: np. w dokumentacji modeli OpenAI widnieją daty cutoff (dla konkretnych wariantów modeli), a w notach produktowych pojawiają się informacje o „nowszym knowledge cutoff” w kolejnych generacjach. Dlaczego to w ogóle występuje? W uproszczeniu: trening modeli jest kosztowny, wieloetapowy i wymaga kontroli jakości oraz bezpieczeństwa; dlatego baza wiedzy w parametrach modelu odzwierciedla stan świata z określonego momentu, a nie jego ciągłe zmiany. Model jest najpierw trenowany na dużym zbiorze danych, a po wdrożeniu nie uczy się już sam – tylko wykorzystuje to, czego nauczył się wcześniej. Badania nad retrieval od lat opisują ten fundamentalny problem: wiedza „zaszyta” w parametrach jest trudna do aktualizowania i skalowania, dlatego rozwijano podejścia, które łączą pamięć parametryczną (model) z pamięcią nieparametryczną (indeks dokumentów / retriever). To właśnie ta koncepcja stoi u podstaw rozwiązań takich jak RAG czy REALM. W praktyce część dostawców wprowadza jeszcze jedno rozróżnienie: oprócz „training data cutoff” podaje też „reliable knowledge cutoff” (czyli okres, w którym wiedza jest najbardziej kompletna i wiarygodna). To ważne biznesowo, bo pokazuje, że nawet jeśli w danych treningowych „coś” było, to nie musi to być równie stabilne i dobrze „utrwalone” w zachowaniu modelu.

2. Jak cutoff wpływa na wiarygodność odpowiedzi w biznesie
Najważniejsze ryzyko jest pozornie banalne: model może nie znać zdarzeń po cutoff, więc przy pytaniach o aktualny stan rynku albo bieżące reguły operacyjne będzie „zgadywał” lub uogólniał. Dostawcy wprost sugerują użycie narzędzi typu web/file search, aby uzupełnić lukę między treningiem a teraźniejszością.
W praktyce pojawiają się trzy klasy problemów:
Pierwsza to nieaktualność: model może podawać poprawne kiedyś informacje, ale błędne dziś. To szczególnie dotkliwe w scenariuszach:
- obsługa klienta (zmienione warunki gwarancji, nowe cenniki, wycofane produkty),
- sprzedaż i zakupy (ceny, dostępność, kursy walut, regulacje importowe),
- compliance i prawo (zmiany przepisów, interpretacje, terminy),
- IT/operacje (incydenty, statusy usług, wersje oprogramowania, polityki bezpieczeństwa).
Sam fakt, że modele mają formalnie podawane daty cutoff w dokumentacjach, jest sygnałem: bez retrieval nie należy zakładać aktualności.
Druga to halucynacje i nadmierna pewność: LLM potrafi generować wypowiedzi spójne językowo, ale niezgodne z faktami — w tym „wymyślone” szczegóły, cytowania czy nazwy. To zjawisko jest na tyle powszechne, że istnieją obszerne przeglądy naukowe i analizy przyczyn, a dostawcy publikują osobne materiały wyjaśniające, skąd się bierze „zmyślanie” w modelach.
Trzecia to błąd systemowy w procesie biznesowym: koszt nie polega na tym, że AI „napisała brzydkie zdanie”, tylko że zasiliła decyzję operacyjną nieaktualną informacją. Dokumentacje wdrożeniowe zwracają uwagę, by definiować jakość przez pryzmat kosztu porażki (np. zły zwrot, zła decyzja kredytowa, błędne zobowiązanie wobec klienta), a nie przez „ładność” odpowiedzi.
W praktyce oznacza to, że w firmie warto traktować odpowiedzi modeli jako:
- pomoc w analizie i syntezie, gdy kontekst jest dostarczony (RAG/API/web),
- hipotezę do weryfikacji, gdy pytanie dotyczy faktów dynamicznych.
3. Metody obejścia cutoff i uzyskania aktualnej wiedzy w czasie zapytania
Poniżej są metody techniczne i produktowe, które w biznesowych wdrożeniach najczęściej „domykają” problem knowledge cutoff. Kluczowa idea: model nie musi „wiedzieć” wszystkiego w parametrach, jeśli potrafi pobrać właściwy kontekst tuż przed wygenerowaniem odpowiedzi.
3.1 Wyszukiwanie internetu w czasie rzeczywistym
To najprostsza mentalnie metoda: LLM dostaje narzędzie „web search” i może pobrać świeże źródła, a potem odpowiedź „uziemić” w wynikach wyszukiwania (często z cytowaniami). W dokumentacji kilku dostawców jest to wprost opisane jako działanie beyond its knowledge cutoff.
Przykładowo:
- narzędzie web search w API może pozwalać na zwracanie odpowiedzi z cytowaniami, a model — zależnie od konfiguracji — decyduje, czy szukać czy odpowiadać bez szukania.
- niektóre platformy zwracają też metadane uziemienia (zapytania, linki, mapowanie fragmentów odpowiedzi do źródeł), co ułatwia audyt i UI z przypisami.
3.2 Łączenie z API i źródłami zewnętrznymi
W biznesie „prawdą” często jest system źródłowy: ERP, CRM, PIM, system cenowy, dane logistyczne, hurtownia lub dostawcy danych rynkowych. Wtedy zamiast web search lepsze jest wywołanie API (narzędzie/funkcja), które zwraca „jedyną wersję prawdy”, a model ma za zadanie:
- dobrać właściwe zapytanie,
- zinterpretować wynik,
- opisać go użytkownikowi w zrozumiały sposób.
Ten wzorzec jest spójny z logiką „tool use”: model generuje odpowiedź dopiero po pobraniu danych narzędziami.
3.3 Retrieval‑Augmented Generation (RAG)
RAG to architektura, w której przed generowaniem odpowiedzi wykonuje się retrieval (wyszukanie) w korpusie dokumentów, a następnie dołącza znalezione fragmenty do promptu. W literaturze jest to opisywane jako połączenie pamięci parametrycznej i nieparametrycznej.
W praktyce firmowej RAG najczęściej służy do:
- instrukcji produktowych i procedur operacyjnych,
- polityk wewnętrznych (HR, IT, bezpieczeństwo),
- baz wiedzy (help center),
- dokumentacji technicznej, umów i regulaminów,
- repozytoriów projektowych (notatki, decyzje architektoniczne).
Ważna obserwacja z dokumentacji wdrożeniowej: RAG jest szczególnie potrzebny, gdy modelowi brakuje kontekstu, gdy jego wiedza jest nieaktualna lub gdy potrzebujesz kontekstu zastrzeżonego (proprietary).
3.4 Fine‑tuning i „ciągłe uczenie”
Fine-tuning (dostrajanie) jest użyteczny, ale nie jest najbardziej ekonomiczną metodą „dogrywania świeżej wiedzy”. W praktyce fine-tuning stosuje się głównie po to, by:
- poprawić skuteczność na konkretnym typie zadania,
- uzyskać stabilniejszy format/ton,
- albo osiągnąć podobny wynik mniejszym kosztem (mniej tokenów / mniejszy model).
Jeżeli problemem jest aktualność lub kontekst firmowy, dokumentacje wdrożeniowe częściej kierują w stronę RAG i optymalizacji kontekstu niż w stronę „przetrenujmy model”.
„Ciągłe uczenie” (online learning) w foundation models jest w praktyce rzadkie wprost — częściej spotyka się cykliczne wydania nowych wersji modeli i dołączanie retrieval/tooling jako warstwy aktualizacji w czasie zapytania. Dobrym sygnałem jest też to, że karty modeli potrafią deklarować model jako statyczny i trenowany offline, a aktualizacje pojawiają się jako „przyszłe wersje”.
3.5 Systemy hybrydowe
Najczęstszy „optymalny” wariant enterprise to hybryda:
- RAG na dokumentach firmowych,
- API na danych transakcyjnych i raportowych,
- web search tylko w kontrolowanych przypadkach (np. analiza rynku), z wymuszoną atrybucją i filtrami źródeł.
Tabela porównawcza metod
| Metoda | Aktualność | Koszt | Złożoność wdrożenia | Ryzyko | Skalowalność |
|---|---|---|---|---|---|
| RAG (wewnętrzne dokumenty) | wysoka (tak świeża jak indeks) | średni (indeksowanie + storage + inferencja) | średnia-wysoka | średnie (jakość danych, prompt injection w retrieval) | wysoka |
| Live web search | bardzo wysoka | zmienna (narzędzia + tokeny + zależność od dostawcy) | niska-średnia | wysokie (jakość web, manipulacje, compliance) | wysoka (ale zależna od limitów i kosztów) |
| Integracje API (systemy źródłowe) | bardzo wysoka („single source of truth”) | średni (integracje + utrzymanie) | średnia | średnie (błędy integracji, dostęp, audyt) | bardzo wysoka |
| Fine-tuning | średnia (zależna od aktualności danych treningowych) | średni-wysoki | średnia-wysoka | średnie (regresje, drift, utrzymanie wersji) | wysoka (gdy proces MLOps dojrzały) |
W tle tej tabeli są dwa ważne fakty: (1) RAG i retrieval są wymieniane jako kluczowe dźwignie poprawy trafności, gdy problemem jest brak/nieaktualność kontekstu, a (2) narzędzia web search bywają opisywane jako sposób na pozyskanie informacji beyond knowledge cutoff z cytowaniami.
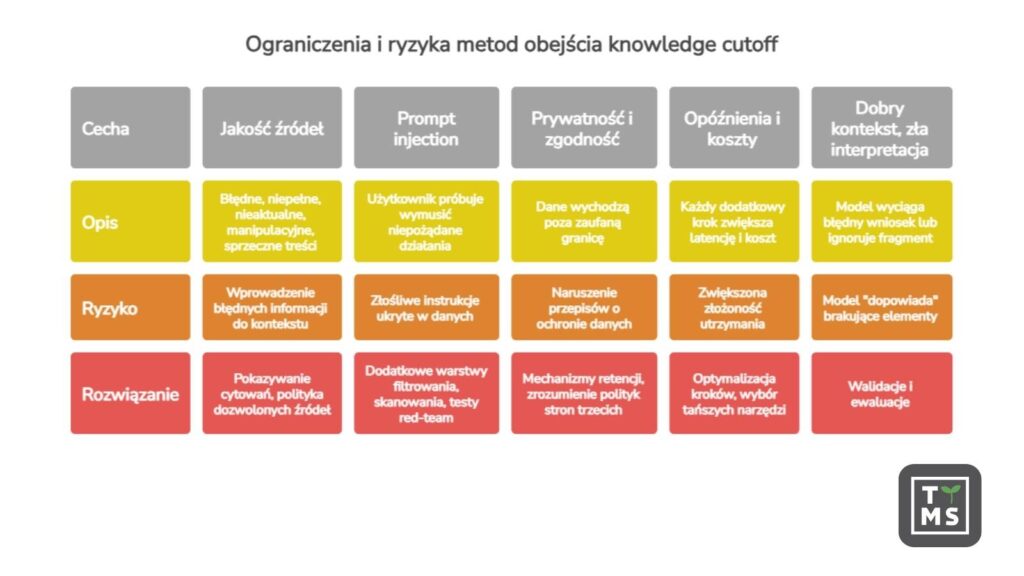
4. Ograniczenia i ryzyka metod obejścia cutoff
To, że potrafimy „dostarczyć świeże dane”, nie oznacza, że system nagle staje się bezbłędny. W firmie liczą się ograniczenia, które najczęściej decydują o tym, czy wdrożenie jest bezpieczne i opłacalne.
4.1 Jakość i „prawdziwość” źródeł
Web search i nawet RAG mogą wciągnąć do kontekstu treści:
- błędne, niepełne albo nieaktualne,
- SEO‑spam lub treści celowo manipulacyjne,
- sprzeczne między źródłami.
Dlatego praktyką staje się pokazywanie cytowań/źródeł oraz polityka dozwolonych źródeł dla zastosowań wrażliwych (finanse, prawo, medycyna).
4.2 Prompt injection
W systemach z narzędziami rośnie powierzchnia ataku. Najbardziej klasyczne ryzyko to prompt injection: użytkownik (albo treść w źródle danych) próbuje wymusić na modelu niepożądane działania lub obejście reguł.
Szczególnie groźne w firmie jest indirect prompt injection: złośliwe instrukcje są ukryte w danych, do których system ma dostęp (np. dokumenty, maile, strony WWW pobierane przez web/RAG), i dopiero potem trafiają do promptu jako „kontekst”. Ten problem jest już opisywany zarówno w publikacjach naukowych, jak i w analizach instytucji zajmujących się bezpieczeństwem GenAI. Dla biznesu to oznacza konieczność dodatkowych warstw: filtrowania treści, skanowania, zasad „co wolno narzędziom”, oraz testów red‑team.
4.3 Prywatność, rezydencja danych i granice zgodności
W praktyce „aktualność” często kosztuje tym, że dane wychodzą poza zaufaną granicę.
- W środowiskach API można ustawiać mechanizmy retencji i tryby typu Zero Data Retention, ale trzeba rozumieć, że niektóre funkcje (np. narzędzia i usługi stron trzecich, konektory) mają własne polityki retencji.
- Część integracji web search (np. w konkretnych usługach chmurowych) explicite ostrzega, że dane mogą wyjść poza granicę zgodności/geo i że dodatkowe aneksy ochrony danych mogą nie obejmować takiego przepływu. To ma bezpośrednie konsekwencje prawne i kontraktowe, zwłaszcza w UE.
- Niektóre narzędzia web search mają warianty różniące się kompatybilnością z „zero retention” (np. nowsze wersje mogą wymagać wewnętrznego wykonania kodu do filtrowania wyników, co zmienia własności prywatności).
4.4 Opóźnienia i koszty
Każdy dodatkowy krok (web search, retrieval, wywołanie API, reranking) to:
- większa latencja,
- wyższy koszt (tokeny + opłaty za narzędzia / wywołania),
- większa złożoność utrzymania.
W dokumentacji modeli wprost widać, że narzędzia typu search mogą być rozliczane osobno („fee per tool call”), a web search w usługach chmurowych ma swój cennik.
4.5 Ryzyko „dobry kontekst, zła interpretacja”
Nawet przy świetnym retrieval model może:
- wyciągnąć z kontekstu błędny wniosek,
- zignorować kluczowy fragment,
- albo „dopowiedzieć” brakujące elementy.
Dlatego dojrzałe wdrożenia mają walidacje i ewaluacje, a nie tylko „podłączony indeks”.
5. Porównanie podejść konkurencji
Poniżej porównanie jest „operacyjne”: nie kto ma lepszy benchmark, ale jak dostawcy rozwiązują problem aktualności i integracji danych.
Wspólny mianownik: każdy duży dostawca w praktyce uznaje, że sama „wiedza w parametrach” nie wystarcza i oferuje narzędzia do grounding/retrieval albo partnerstwa wyszukiwarkowe.
5.1 Tabela porównawcza dostawców i mechanizmów aktualizacji
| Dostawca | Rodzina modeli (przykłady) | Mechanizmy aktualizacji/grounding | Real-time dostępność | Integracje (typowe) |
|---|---|---|---|---|
| OpenAI | GPT | Narzędzia w API: web search + file search (vector stores) w czasie rozmowy; cykliczne aktualizacje modeli/cutoff | tak (web search), zależnie od konfiguracji | vector stores, narzędzia, konektory/serwery MCP (zewnętrzne) |
| Gemini / (historycznie: PaLM) | Grounding z Google Search; zwracanie metadanych uziemienia i cytowań | tak (Search) | integracje ekosystemu Google (narzędzia, URL context) | |
| Anthropic | Claude | Web search tool w API z cytowaniami; wersje narzędzia różnią się filtracją i właściwościami ZDR | tak (web search) | narzędzia (tool use), integracje przez API |
| Microsoft | Copilot / modele w Azure | Web search (preview) w Azure z grounding (Bing); retrieval i grounding w danych M365 przez semantic indexing/Graph | tak (web), tak (M365 retrieval) | M365 (SharePoint/OneDrive), semantic index, web grounding |
| Meta Platforms | Llama / Meta AI | W modelach open‑weight: aktualizacja przez wydania nowych wersji; w produktach: partnerstwa wyszukiwarkowe dla real‑time | tak (w Meta AI przez search partnerstwa) | open‑source ekosystem + integracje w aplikacjach Meta |
Źródłowo: web search i file search jako „most” między cutoff a teraźniejszością w API są opisane wprost. Google dokumentuje grounding z Search jako real-time i beyond knowledge cutoff wraz z cytowaniami. Anthropic dokumentuje web search tool i automatyczne cytowania, a także niuanse ZDR zależne od wersji narzędzia. Microsoft opisuje web search (preview) z grounding oraz ważne konsekwencje prawne przepływu danych; osobno opisuje semantic indexing jako grounding w danych organizacji. Meta deklaruje wprost partnerstwo wyszukiwarkowe zapewniające real-time informacje w czatach oraz publikuje daty cutoff w kartach modeli Llama (np. Llama 3).
Warto też zauważyć, że niektórzy dostawcy podają dość precyzyjnie daty cutoff dla kolejnych wersji modeli (np. w notach produktowych i kartach modeli), co jest praktycznym sygnałem dla biznesu: „wersjonujcie zależności, mierzcie regresje, planujcie upgrade’y”.
6. Rekomendacje dla firm i przykłady zastosowań
Ta sekcja jest celowo pragmatyczna. Nie znam Twoich parametrów (branża, skala, budżet, tolerancja na błąd, wymagania prawne, geografie danych). W związku z tym rekomendacje są „szablonem decyzyjnym”, który trzeba dostroić.
6.1 Architektura referencyjna dla biznesu
Najczęściej sprawdza się architektura warstwowa:
Warstwa danych i źródeł:
- „systemy prawdy” (ERP/CRM/BI) przez API,
- wiedza nieustrukturyzowana (dokumenty) przez RAG,
- świat zewnętrzny (web) tylko tam, gdzie to ma sens i jest zgodne z polityką.
Warstwa orkiestracji i polityk:
- klasyfikacja zapytań: Czy potrzebna jest aktualność? Czy to jest pytanie o fakt? Czy wolno użyć web?
- polityka źródeł: allowlista domen/typów, „tier” zaufania, wymaganie cytowania,
- polityka działań: co model może wykonać (np. nie może „sam” wysłać maila/zmienić rekordu bez zatwierdzenia).
Warstwa jakości i audytu:
- logi: pytanie, użyte narzędzia, źródła, wynik,
- testy regresji (zestawy pytań biznesowych),
- metryki: accuracy@k dla retrieval, odsetek odpowiedzi z cytowaniami, czas odpowiedzi, koszt/1000 zapytań,
- eskalacja do człowieka, gdy model nie ma źródeł albo wykryto niepewność.
6.2 Procesy weryfikacji, SLA i monitoring
Praktyka, która „robi różnicę”:
- Zdefiniuj SLA nie jako „LLM zawsze ma rację”, tylko jako: czas odpowiedzi, minimalny poziom cytowania, maksymalny koszt na zapytanie, maksymalny odsetek incydentów (np. błędne informacje w krytycznych kategoriach). Punkt odniesienia to koszt porażki opisany w dokumentacjach optymalizacji jakości.
- Wprowadź klasy ryzyka: „informacyjne” vs „operacyjne” (np. automatyczna zmiana w systemie). Dla operacyjnych stosuj zatwierdzenia i ograniczoną agentowość (human-in-the-loop).
- Dla web search i narzędzi zewnętrznych sprawdź konsekwencje prawne przepływu danych (geo boundary, DPA, retencja).
Jeśli działasz w UE i przypadek użycia może wpaść w kategorie regulowane (np. decyzje dot. zatrudnienia, kredytu, edukacji, infrastruktury), warto mapować wymagania pod kątem „systemu zarządzania ryzykiem” i nadzoru człowieka (to jest kierunek, który formalizuje prawo i standardy).
6.3 Krótkie studium przypadków
Obsługa klienta (contact center + baza wiedzy)
Cel: skrócić czas odpowiedzi i ujednolicić komunikację.
Architektura: RAG na aktualnej bazie wiedzy + uprawnienia do pobierania statusów zamówień przez API + zakaz web search (żeby nie mieszać w politykach).
Ryzyko: prompt injection przez treści w ticketach / mailach; w praktyce trzeba filtrować i odróżniać „treść” od „instrukcji”.
Analiza rynku (research dla sprzedaży/strategii)
Cel: szybkie streszczenia trendów i sygnałów z rynku.
Architektura: web search z cytowaniami + polityka źródeł (tier 1: oficjalne raporty, regulatorzy, agencje danych; tier 2: media branżowe) + obowiązkowe cytowania w odpowiedzi.
Ryzyko: źródła niskiej jakości lub manipulacje; dlatego cytowania i różnorodność źródeł są krytyczne.
Compliance / polityki wewnętrzne
Cel: odpowiadać pracownikom „co wolno” zgodnie z aktualnymi procedurami.
Architektura: wyłącznie RAG na zatwierdzonych wersjach dokumentów + wersjonowanie + logowanie źródeł.
Ryzyko: „aktualność indeksu” i kontrola dostępu; dobrze pasuje do rozwiązań, które utrzymują dane „in place” i respektują uprawnienia.
7. Podsumowanie i checklista wdrożeniowa
Knowledge cutoff nie jest „wadą” konkretnego dostawcy — to cecha sposobu, w jaki duże modele są trenowane i wydawane. Biznesowa niezawodność nie polega więc na szukaniu „modelu bez cutoff”, tylko na zaprojektowaniu systemu, który dostarcza świeży kontekst w czasie zapytania i ma kontrolę ryzyk.
7.1 Checklista działań do wdrożenia
-
- Zidentyfikuj klasy pytań, które wymagają świeżości (np. ceny, prawo, statusy) i które mogą działać na wiedzy statycznej.
- Wybierz mechanizm aktualności: API (system of record) / RAG (dokumenty) / web search (rynek) — nie wszystko naraz w pierwszej iteracji.
- Ustal politykę źródeł i wymóg cytowań (zwłaszcza dla analiz rynkowych i twierdzeń faktograficznych).
- Wprowadź zabezpieczenia przed prompt injection (bezpośrednie i pośrednie): filtrowanie treści, separacja instrukcji od danych, testy red-team.
- Zdefiniuj retencję, rezydencję danych i zasady przekazywania danych do usług zewnętrznych (geo boundary / DPA / ZDR).
- Zbuduj zestaw ewaluacji (z realnych przypadków), mierz koszt błędu i ustaw progi eskalacji do człowieka.
- Zaplanuj wersjonowanie i aktualizacje: zarówno modeli (upgrade), jak i indeksów (odświeżanie RAG).
8. AI bez aktualnych danych to ryzyko. Jak temu zapobiec?
W praktyce największym wyzwaniem nie jest dziś samo wykorzystanie AI, ale zapewnienie mu dostępu do aktualnych, wiarygodnych danych. To właśnie na styku modeli językowych, systemów źródłowych i procesów biznesowych powstaje realna wartość – albo ryzyko. W TTMS pomagamy projektować i wdrażać architektury, które łączą AI z danymi w czasie rzeczywistym – od integracji z systemami, przez rozwiązania RAG, aż po mechanizmy kontroli jakości i bezpieczeństwa. Jeśli zastanawiasz się, jak to podejście zastosować w Twojej organizacji, warto zacząć od rozmowy o konkretnych scenariuszach. Skontaktuj się z nami!

FAQ
Czy AI może podejmować decyzje biznesowe bez dostępu do aktualnych danych?
W teorii model językowy może wspierać decyzje na podstawie wzorców i wiedzy historycznej, ale w praktyce jest to ryzykowne. W wielu procesach biznesowych kluczowe są dane zmienne — ceny, dostępność, przepisy, statusy operacyjne. Bez ich uwzględnienia model może generować logiczne, ale nieaktualne rekomendacje. Problem polega na tym, że takie odpowiedzi często brzmią bardzo wiarygodnie, co utrudnia wychwycenie błędu.
Dlatego w firmach AI nie powinno być traktowane jako autonomiczny decydent, lecz jako element wspierający proces, który zawsze ma dostęp do aktualnych danych lub podlega kontroli. W praktyce oznacza to integrację z systemami źródłowymi oraz wprowadzenie mechanizmów walidacji. W wielu przypadkach stosuje się również podejście „human-in-the-loop”, gdzie człowiek zatwierdza kluczowe decyzje. To szczególnie ważne w obszarach takich jak finanse, compliance czy operacje.
Jak rozpoznać, że AI w firmie działa na nieaktualnych danych?
Najczęstszy sygnał to subtelne rozbieżności między odpowiedziami AI a rzeczywistością operacyjną. Może to być np. podawanie nieaktualnych cen, błędnych procedur lub odwoływanie się do już zmienionych zasad. Problem polega na tym, że pojedyncze błędy często są ignorowane, dopóki nie zaczną wpływać na wyniki biznesowe.
Dobrym podejściem jest wprowadzenie testów kontrolnych — zestawu pytań, które wymagają aktualnej wiedzy i pozwalają szybko wykryć ograniczenia systemu. Warto również analizować logi odpowiedzi i porównywać je z danymi systemowymi. W bardziej zaawansowanych wdrożeniach stosuje się monitoring jakości odpowiedzi oraz alerty przy wykryciu potencjalnych niezgodności.
Kluczowe jest też pytanie: czy AI „wie, że nie wie”. Jeśli model nie sygnalizuje braku aktualnych danych, ryzyko rośnie. Dlatego coraz częściej wdraża się mechanizmy wymuszające wskazanie źródła informacji lub poziomu pewności odpowiedzi.
Czy RAG rozwiązuje wszystkie problemy z aktualnością danych?
RAG znacząco poprawia dostęp do aktualnych informacji, ale nie jest rozwiązaniem uniwersalnym. Jego skuteczność zależy od jakości danych, sposobu ich indeksowania oraz mechanizmów wyszukiwania. Jeśli dokumenty są nieaktualne, niespójne lub źle przygotowane, system będzie zwracał błędne lub mylące odpowiedzi.
Dodatkowym wyzwaniem jest kontekst — model może otrzymać poprawne dane, ale źle je zinterpretować lub pominąć kluczowy fragment. Dlatego RAG wymaga nie tylko infrastruktury, ale też zarządzania treścią i jakości danych. W praktyce oznacza to konieczność regularnego aktualizowania indeksów, kontroli wersji dokumentów i testowania wyników.
W wielu przypadkach RAG najlepiej działa jako część większego systemu, który łączy różne źródła danych — np. dokumenty, API i dane operacyjne. Dopiero takie podejście pozwala osiągnąć wysoką jakość i wiarygodność odpowiedzi.
Jakie są największe ukryte koszty wdrożenia AI z dostępem do danych?
Najczęściej niedoszacowanym kosztem jest integracja. Podłączenie AI do systemów takich jak ERP, CRM czy hurtownie danych wymaga pracy architektonicznej, zapewnienia bezpieczeństwa i często dostosowania istniejących procesów. Kolejnym elementem są koszty utrzymania — aktualizacja danych, monitoring jakości, zarządzanie dostępami.
Dochodzi do tego koszt błędów. Jeśli system AI podejmie niewłaściwą decyzję lub przekaże nieprawidłową informację klientowi, konsekwencje mogą być znacznie większe niż koszt samego rozwiązania. Dlatego coraz więcej firm analizuje ROI nie tylko przez pryzmat automatyzacji, ale też redukcji ryzyka.
Warto też uwzględnić koszty operacyjne, takie jak czas odpowiedzi (latencja) czy zużycie zasobów przy korzystaniu z zewnętrznych narzędzi i API. Ostatecznie najbardziej opłacalne są rozwiązania dobrze zaprojektowane od początku, a nie takie, które „dokleja się” do istniejących procesów.
Czy da się wdrożyć AI w firmie bez ryzyka naruszenia bezpieczeństwa danych?
Tak, ale wymaga to świadomego podejścia architektonicznego. Kluczowe jest określenie, jakie dane mogą być przetwarzane przez model i gdzie fizycznie się znajdują. W wielu przypadkach stosuje się rozwiązania, które nie przenoszą danych poza środowisko organizacji, a jedynie umożliwiają ich bezpieczne przeszukiwanie.
Istotne są również mechanizmy kontroli dostępu – AI powinno widzieć tylko te dane, do których użytkownik ma uprawnienia. W bardziej zaawansowanych systemach stosuje się dodatkowo anonimizację, maskowanie danych oraz logowanie wszystkich operacji.
Nie można też zapominać o zagrożeniach takich jak prompt injection, które mogą prowadzić do nieautoryzowanego dostępu do informacji. Dlatego wdrożenie AI powinno być traktowane podobnie jak każdy inny system krytyczny – z pełnym uwzględnieniem polityk bezpieczeństwa, audytów i monitoringu. Przy odpowiednim podejściu AI może być nie tylko bezpieczne, ale wręcz poprawiać kontrolę nad danymi i procesami.






