Nowoczesne systemy AI, a w szczególności duże modele językowe (LLM), działają w zupełnie inny sposób niż tradycyjne oprogramowanie. Myślą w tokenach (podjednostkach języka), generując odpowiedzi w sposób probabilistyczny. Dla liderów biznesowych wdrażających aplikacje oparte na LLM wiąże się to z nowymi wyzwaniami dotyczącymi monitorowania i zapewniania niezawodności. LLM observability stało się kluczową praktyką, która pozwala upewnić się, że systemy AI zachowują niezawodność, efektywność i bezpieczeństwo w środowisku produkcyjnym. W tym artykule wyjaśniamy, czym jest LLM observability, dlaczego jest potrzebne i jak je wdrożyć w środowisku korporacyjnym.
1. Czym jest LLM observability (i dlaczego tradycyjne monitorowanie nie wystarcza)?
W klasycznym monitorowaniu IT śledzimy serwery, API lub mikroserwisy pod kątem dostępności, błędów i wydajności. Ale LLM to nie standardowa usługa – to złożony model, który może zawodzić w subtelny sposób, nawet jeśli infrastruktura wygląda na zdrową. LLM observability oznacza praktykę śledzenia, mierzenia i rozumienia, jak LLM działa w środowisku produkcyjnym – poprzez łączenie danych wejściowych, wyjściowych i wewnętrznych procesów modelu. Celem jest poznanie dlaczego model odpowiedział w taki sposób (lub dlaczego zawiódł) – a nie tylko sprawdzenie, czy system działa.
Tradycyjne narzędzia do logowania i APM (monitorowania wydajności aplikacji) nie zostały stworzone do tego celu. Mogą powiedzieć, że żądanie do modelu zakończyło się sukcesem (200 OK) i trwało 300 ms, ale nie pokażą, czy odpowiedź była merytorycznie poprawna lub adekwatna kontekstowo. Przykładowo, chatbot AI może być dostępny i szybko odpowiadać, a mimo to stale udzielać błędnych lub bezsensownych odpowiedzi – tradycyjne monitory pokażą „zielone światło”, podczas gdy użytkownicy będą otrzymywać błędne informacje. Dzieje się tak, ponieważ klasyczne narzędzia koncentrują się na metrykach systemowych (CPU, pamięć, błędy HTTP), podczas gdy problemy z LLM tkwią często w treści odpowiedzi (np. ich zgodność z faktami lub adekwatność tonu wypowiedzi). Krótko mówiąc, standardowe monitorowanie odpowiada na pytanie „Czy system działa?”; LLM observability odpowiada na pytanie „Dlaczego otrzymaliśmy taką odpowiedź?”.
Kluczowe różnice obejmują głębokość i kontekst. LLM observability sięga głębiej, łącząc dane wejściowe, wyjściowe i wewnętrzne procesy modelu, aby ujawnić pierwotne przyczyny. Może wskazać, który prompt użytkownika doprowadził do błędu, jakie pośrednie kroki podjął model i jak podjął decyzję o odpowiedzi. Śledzi także specyficzne dla AI problemy, takie jak halucynacje czy uprzedzenia, i koreluje zachowanie modelu z wynikami biznesowymi (takimi jak satysfakcja użytkowników czy koszty). Tradycyjne monitorowanie może wykryć awarię lub skok opóźnień, ale nie jest w stanie wyjaśnić, dlaczego dana odpowiedź była błędna lub szkodliwa. W przypadku LLM potrzebujemy bogatszej telemetrii, która pozwoli zajrzeć w „proces decyzyjny” modelu, aby skutecznie nim zarządzać.
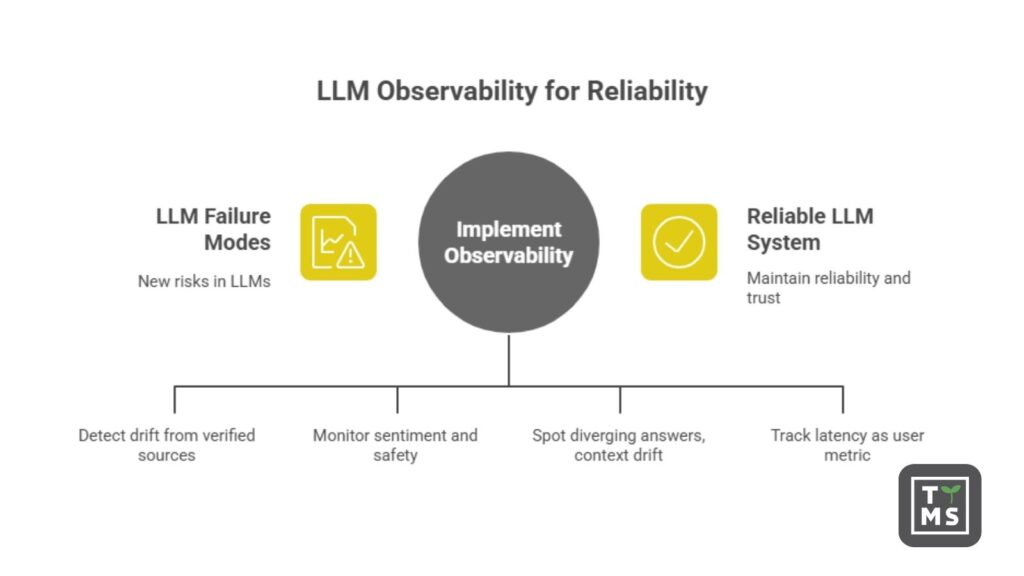
2. Nowe wyzwania w monitorowaniu: halucynacje, toksyczność, niespójność, opóźnienia
Wdrożenie LLM wprowadza nowe rodzaje błędów i ryzyk, które nie istniały w tradycyjnych aplikacjach. Zespoły biznesowe muszą monitorować następujące problemy:
- Halucynacje (zmyślone odpowiedzi): LLM potrafią z dużą pewnością generować informacje, które są fałszywe lub nieoparte na żadnym źródle. Przykładowo, asystent AI może wymyślić szczegóły polityki firmy albo powołać się na nieistniejące badanie. Takie halucynacje mogą wprowadzać użytkowników w błąd lub prowadzić do błędnych decyzji biznesowych. Narzędzia observability mają na celu wykrycie sytuacji, gdy odpowiedzi „odchodzą od zweryfikowanych źródeł”, tak by można było je wychwycić i poprawić. Często wiąże się to z oceną faktograficzności odpowiedzi (porównanie z bazami danych lub użycie drugiego modelu) i oznaczaniem odpowiedzi z wysokim „wskaźnikiem halucynacji” do przeglądu.
- Treści toksyczne lub uprzedzone: Nawet dobrze wytrenowane modele mogą okazjonalnie generować obraźliwe, uprzedzone lub niestosowne wypowiedzi. Bez monitoringu jedna toksyczna odpowiedź może dotrzeć do klienta i zaszkodzić marce. LLM observability oznacza śledzenie nastroju i bezpieczeństwa odpowiedzi – np. za pomocą klasyfikatorów toksyczności lub filtrów słów kluczowych – i eskalowanie potencjalnie szkodliwych treści. Jeśli AI zaczyna generować uprzedzone rekomendacje lub niestosowne komentarze, system observability ostrzeże zespół, by mógł zainterweniować (lub przekazać sprawę do przeglądu przez człowieka).
- Niespójności i dryf kontekstowy: W rozmowach wieloetapowych LLM mogą sobie zaprzeczać lub tracić kontekst. Agent AI może w jednej chwili udzielić poprawnej odpowiedzi, a chwilę później sprzecznej lub niezrozumiałej – zwłaszcza przy długiej rozmowie. Takie niespójności frustrują użytkowników i podważają zaufanie. Monitorowanie ścieżek rozmów pomaga wykryć, kiedy odpowiedzi modelu zaczynają się rozchodzić albo gdy zapomina wcześniejsze informacje (oznaka dryfu kontekstowego). Dzięki logowaniu całych sesji zespoły mogą rozpoznać, kiedy spójność AI słabnie – np. ignoruje wcześniejsze polecenia lub zmienia ton – i odpowiednio dostosować prompty lub dane treningowe.
- Opóźnienia i skoki wydajności: LLM są obciążające obliczeniowo, a czas odpowiedzi może zależeć od obciążenia, długości promptu czy złożoności modelu. Liderzy biznesowi powinni śledzić opóźnienia nie tylko jako metrykę IT, ale także jako wskaźnik doświadczenia użytkownika. Pojawiają się nowe metryki, takie jak Time to First Token (TTFT) – czas do wygenerowania pierwszego tokenu – oraz liczba tokenów na sekundę. Niewielkie opóźnienie może oznaczać lepsze odpowiedzi (gdy model „myśli” intensywniej), albo wskazywać na wąskie gardło. Monitorując opóźnienia razem z jakością odpowiedzi, można znaleźć optymalny balans. Na przykład, jeśli 95. percentyl TTFT przekracza 2 sekundy, dashboard może to oznaczyć i inżynierowie SRE mogą sprawdzić, czy przyczyną jest aktualizacja modelu lub problem z GPU. Zapewnienie szybkich odpowiedzi to nie tylko kwestia IT – to klucz do zaangażowania i satysfakcji użytkowników.
To tylko kilka przykładów. Inne kwestie, jak ataki typu prompt injection (złośliwe dane wejściowe próbujące zmylić AI), nadmierne zużycie tokenów (mogące znacząco zwiększyć koszty API) czy wysoki wskaźnik błędów i odmów odpowiedzi, również są istotne do monitorowania. Podstawowy wniosek jest taki, że LLM wprowadzają jakościowo nowe sposoby „awarii” – odpowiedź może być błędna lub niebezpieczna, mimo że system nie zgłasza żadnego błędu. Observability działa jak system wczesnego ostrzegania dla tych specyficznych dla AI problemów, pomagając utrzymać niezawodność i zaufanie do systemu.
3. Śledzenie LLM: Śledzenie procesu myślowego AI (token po tokenie)
Jednym z najważniejszych elementów observability w LLM jest trace LLM. W architekturach mikroserwisowych stosujemy śledzenie rozproszone, aby prześledzić żądanie użytkownika między usługami (np. trace pokazuje, że Serwis A wywołuje Serwis B, itd., wraz z czasami). W przypadku LLM zapożyczamy tę ideę, by prześledzić żądanie przez etapy przetwarzania AI – czyli, zasadniczo, prześledzić „proces myślowy” modelu krok po kroku, token po tokenie.
Trace LLM to jak opowieść o tym, jak powstała odpowiedź AI. Może zawierać: pierwotny prompt użytkownika, dodane prompty systemowe lub kontekstowe, surowy tekst wygenerowany przez model, a nawet rozumowanie krok po kroku, jeśli AI korzystało z narzędzi lub działało w ramach agenta. Zamiast pojedynczego wpisu w logu, trace łączy wszystkie zdarzenia i decyzje powiązane z jednym zadaniem AI.
Na przykład, wyobraźmy sobie, że użytkownik zadaje pytanie, które wymaga od AI sprawdzenia bazy danych. Trace może zawierać: zapytanie użytkownika, wzbogacony prompt z danymi pobranymi z repozytorium, pierwszą próbę odpowiedzi modelu i kolejne wywołanie zewnętrznego API, ostateczną odpowiedź oraz wszystkie znaczniki czasu i liczbę tokenów na każdym etapie. Dzięki połączeniu wszystkich powiązanych zdarzeń w spójną sekwencję widzimy nie tylko co AI zrobiło, ale także ile czasu zajęły poszczególne kroki i gdzie coś mogło pójść nie tak.
Kluczowe jest to, że trace LLM działają na poziomie tokenów. Ponieważ LLM generują tekst token po tokenie, zaawansowana obserwowalność powinna rejestrować tokeny w czasie rzeczywistym (lub przynajmniej całkowitą liczbę tokenów użytych w żądaniu). Takie szczegółowe logowanie przynosi wiele korzyści. Pozwala mierzyć koszty (które w przypadku API są zazwyczaj zależne od liczby tokenów) dla każdego zapytania i przypisywać je do konkretnych użytkowników lub funkcji. Umożliwia też dokładne zlokalizowanie miejsca, w którym pojawił się błąd – np. „model działał poprawnie do tokena nr 150, a potem zaczął halucynować”. Dzięki znacznikom czasowym na poziomie tokenów można też analizować, które fragmenty odpowiedzi trwały najdłużej (co może sugerować, że model „dłużej się zastanawiał” lub się zaciął).
Poza tokenami, możemy również zbierać diagnostykę opartą na mechanizmie uwagi (attention) – czyli zaglądać do „czarnej skrzynki” sieci neuronowej modelu. Choć to wciąż rozwijająca się dziedzina, niektóre techniki (nazywane często causal tracing) pozwalają określić, które komponenty wewnętrzne (neurony lub głowy attention) miały największy wpływ na wygenerowanie danej odpowiedzi. Można to porównać do debugowania „mózgu” AI: w przypadku problematycznej odpowiedzi, inżynierowie mogą sprawdzić, która część mechanizmu uwagi spowodowała np. wspomnienie nieistotnego szczegółu. Wstępne badania pokazują, że to możliwe – np. wyłączając niektóre neurony i obserwując, czy ich brak eliminuje halucynację. Choć tego typu tracing jest bardzo techniczny (i zwykle niepotrzebny na co dzień), podkreśla jedną rzecz: observability nie kończy się na zewnętrznych metrykach – może sięgać wnętrza modelu.
W praktyce większość zespołów zaczyna od bardziej ogólnych trace’ów: logowania każdego prompta i odpowiedzi, zbierania metadanych jak wersja modelu, parametry (np. temperatura), czy odpowiedź została odfiltrowana przez mechanizmy bezpieczeństwa. Każdy z tych elementów to jakby „span” w trace’ie mikroserwisu. Łącząc je za pomocą wspólnego ID trace’a, uzyskujemy pełny obraz transakcji AI. To pomaga zarówno przy debugowaniu (można odtworzyć dokładnie ten sam scenariusz, który dał zły wynik), jak i przy optymalizacji wydajności (np. zobaczyć „wodospad” czasów wykonania poszczególnych etapów). Przykładowo trace może ujawnić, że 80% całkowitego opóźnienia zajęło pobieranie dokumentów dla systemu RAG (retrieval-augmented generation), a nie samo wnioskowanie modelu – co daje impuls do optymalizacji wyszukiwania lub cache’owania danych.
Podsumowując: trace’y dla LLM pełnią tę samą rolę co w złożonych architekturach software’owych – pokazują ścieżkę wykonania. Gdy AI „schodzi z kursu”, trace jest mapą, która pozwala znaleźć przyczynę. Jak ujął to jeden z ekspertów ds. observability AI, ustrukturyzowane trace’y LLM dokumentują każdy krok w przepływie pracy AI, zapewniając kluczową widoczność zarówno stanu systemu, jak i jakości wyników.
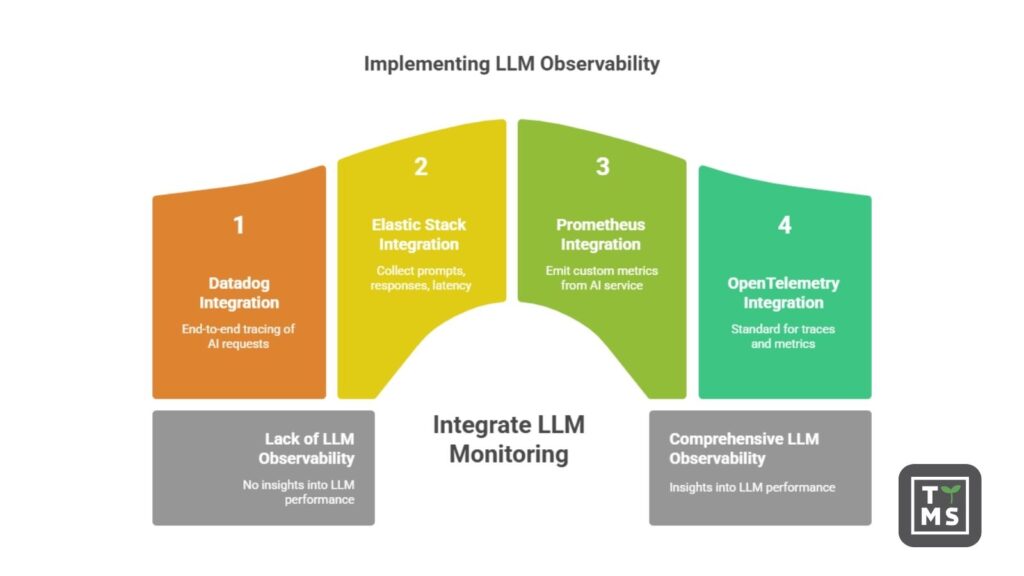
4. Jak włączyć AI do istniejącego stosu monitoringu (Datadog, Kibana, Prometheus itd.)
Jak więc wdrożyć observability dla LLM w praktyce? Dobra wiadomość: nie trzeba wymyślać wszystkiego od nowa. Wiele istniejących narzędzi do observability rozwija wsparcie dla przypadków użycia związanych z AI. Często można zintegrować monitoring LLM z narzędziami i workflow, które Twój zespół już wykorzystuje – od enterprise’owych dashboardów, jak Datadog i Kibana, po rozwiązania open-source, jak Prometheus/Grafana.
- Integracja z Datadog: Datadog (popularna platforma SaaS do monitorowania) wprowadził funkcje wspierające obserwowalność LLM. Umożliwia pełne śledzenie żądań AI obok tradycyjnych trace’ów aplikacji. Na przykład Datadog może zarejestrować każdy prompt i odpowiedź jako osobny span, logować użycie tokenów i opóźnienia, a także oceniać jakość lub bezpieczeństwo odpowiedzi. Dzięki temu można zobaczyć żądanie AI w kontekście całej ścieżki użytkownika. Jeśli Twoja aplikacja webowa wywołuje API LLM, trace w Datadogu pokaże to wywołanie razem z innymi usługami backendowymi, dając wgląd w prompt i wynik. Według opisu produktu Datadoga, ich funkcja LLM Observability oferuje „trace’y w obrębie agentów AI z wglądem w dane wejściowe, wyjściowe, opóźnienia, użycie tokenów i błędy na każdym etapie”. Trace’y LLM są korelowane z danymi APM, co pozwala np. połączyć wzrost błędów modelu z konkretnym wdrożeniem na poziomie mikroserwisów. Dla zespołów już korzystających z Datadoga oznacza to możliwość monitorowania AI z taką samą dokładnością jak reszty stacku – wraz z alertami i dashboardami.
- Integracja ze stosem Elastic (Kibana): Jeśli Twoja organizacja korzysta z ELK/Elastic Stack do logowania i metryk (Elasticsearch, Logstash, Kibana), można go rozszerzyć o dane z LLM. Elastic opracował moduł obserwowalności LLM, który zbiera prompty, odpowiedzi, metryki opóźnień i sygnały bezpieczeństwa do indeksów Elasticsearch. Za pomocą Kibany można wizualizować np. ile zapytań otrzymuje LLM na godzinę, jaki jest średni czas odpowiedzi czy jak często pojawiają się alerty ryzyka. Gotowe dashboardy mogą pokazywać trendy użycia modelu, statystyki kosztowe i alerty moderacji treści w jednym miejscu. Aplikacja AI staje się kolejnym źródłem telemetrycznym zasilającym Elastic. Dodatkową zaletą jest możliwość wykorzystania wyszukiwarki Kibany – np. szybkie filtrowanie odpowiedzi zawierających dane słowo kluczowe lub wszystkich sesji konkretnego użytkownika, w których AI odmówił odpowiedzi. To niezwykle pomocne przy analizie przyczyn błędów (szukanie wzorców w błędach AI) i audytach (np. wyszukiwanie przypadków, gdy AI wspomniał regulowany termin).
- Prometheus i metryki własne: Wiele zespołów inżynieryjnych korzysta z Prometheusa do zbierania metryk (często z Grafaną do wizualizacji). Obserwowalność LLM można tu zrealizować przez wystawienie własnych metryk z Twojej usługi AI. Na przykład Twój wrapper LLM może liczyć tokeny i wystawiać metrykę typu
llm_tokens_consumed_totallub mierzyć opóźnienie metryką histogramowąllm_response_latency_seconds. Metryki te są scrapowane przez Prometheusa jak każde inne. Nowe inicjatywy open source, takie jak llm-d (projekt współtworzony z Red Hat), oferują gotowe metryki dla obciążeń LLM z integracją z Prometheusem i Grafaną. Udostępniają metryki takie jak TTFT, tempo generacji tokenów, czy wskaźnik trafień cache kontekstu. Dzięki temu SRE mogą tworzyć dashboardy Grafany pokazujące np. 95. percentyl TTFT z ostatniej godziny lub wskaźnik trafień cache. Standardowe zapytania PromQL pozwalają też tworzyć alerty: np. uruchomić alert, jeślillm_response_latency_seconds_p95 > 5sekund przez 5 minut lub jeślillm_hallucination_rate(jeśli ją zdefiniujemy) przekroczy próg. Główną zaletą użycia Prometheusa jest elastyczność – można dostosować metryki do najważniejszych aspektów biznesowych (np. liczba zablokowanych nieodpowiednich treści, kategorie promptów) i korzystać z rozbudowanego ekosystemu alertów i wizualizacji Grafany. Zespół Red Hata zauważył, że tradycyjne metryki to za mało dla LLM, dlatego rozszerzenie Prometheusa o metryki świadome tokenów wypełnia lukę w obserwowalności.
Poza tym istnieją inne integracje, takie jak wykorzystanie OpenTelemetry – otwartego standardu do zbierania trace’ów i metryk. Wiele zespołów AI instrumentuje swoje aplikacje za pomocą SDK OpenTelemetry, aby emitować dane śledzenia dla wywołań LLM, które mogą być wysyłane do dowolnego backendu (np. Datadog, Splunk, Jaeger itd.). W rzeczywistości OpenTelemetry stał się powszechnym mostem: na przykład Arize (platforma do obserwowalności AI) używa OpenTelemetry, dzięki czemu można przekierować trace’y z aplikacji do ich systemu bez potrzeby stosowania zastrzeżonych agentów. Oznacza to, że deweloperzy mogą wdrożyć minimalną instrumentację i uzyskać możliwości obserwacji zarówno wewnętrznej, jak i zewnętrznej.
Jakie sygnały powinni śledzić liderzy biznesowi? Wspomnieliśmy już o kilku, ale podsumowując – skuteczny monitoring LLM powinien obejmować mieszankę metryk wydajności (opóźnienia, przepustowość, liczba żądań, zużycie tokenów, błędy) oraz metryk jakości (wskaźnik halucynacji, trafność faktograficzna, adekwatność, toksyczność, opinie użytkowników). Na przykład warto monitorować:
- Średni oraz 95. percentyl czasu odpowiedzi (w celu spełnienia SLA).
- Liczbę żądań dziennie (trend użycia).
- Zużycie tokenów na żądanie i łącznie (kontrola kosztów).
- Embeddingi promptów lub ich kategorie (aby sprawdzić, o co najczęściej pytają użytkownicy i wykrywać zmiany w typie zapytań).
- Wskaźniki sukcesu vs niepowodzeń – choć „niepowodzenie” w przypadku LLM może oznaczać, że model musiał się wycofać lub dał bezużyteczną odpowiedź. Warto samodzielnie zdefiniować, co to znaczy (może być oznaczone przez użytkownika lub przez automatyczną ocenę).
- Flagi moderacji treści (jak często odpowiedź modelu została oznaczona lub musiała zostać przefiltrowana z powodu polityki bezpieczeństwa).
- Wskaźnik halucynacji lub poprawności – możliwy do uzyskania przez automatyczną ścieżkę ewaluacji (np. porównując odpowiedzi z bazą wiedzy lub używając LLM jako sędziego faktograficznego). Może być agregowany w czasie, a jego wzrost powinien przykuć uwagę.
- Sygnały satysfakcji użytkownika – jeśli Twoja aplikacja umożliwia ocenianie odpowiedzi lub śledzi, czy użytkownik musiał przeformułować pytanie (co może sugerować, że pierwsza odpowiedź była nietrafiona), to również cenne sygnały obserwowalności.
Dzięki integracji tych wskaźników z narzędziami takimi jak dashboardy w Datadogu lub Kibanie, liderzy biznesowi zyskują bieżący obraz działania i jakości ich AI. Zamiast bazować na anegdotach lub czekać, aż coś wybuchnie w mediach społecznościowych, masz dane i alerty pod ręką.
5. Ryzyka słabej obserwowalności LLM
Co się stanie, jeśli wdrożysz system LLM, ale nie będziesz go właściwie monitorować? Ryzyka dla przedsiębiorstwa są poważne i często nieoczywiste, dopóki szkody już się nie pojawią. Oto główne obszary ryzyka przy braku obserwowalności LLM.
5.1 Ryzyka prawne i zgodności z przepisami
AI, która generuje niekontrolowane odpowiedzi, może nieumyślnie naruszać regulacje lub polityki firmy. Na przykład chatbot finansowy może udzielić porady, która kwalifikuje się jako nieautoryzowane doradztwo finansowe, albo asystent AI może przypadkowo ujawnić dane osobowe z zestawu treningowego. Bez odpowiednich logów i alertów takie incydenty mogą pozostać niezauważone aż do audytu lub naruszenia danych. Brak możliwości powiązania wyjścia modelu z jego wejściem to koszmar z punktu widzenia zgodności – regulatorzy oczekują możliwości audytu. Jak zauważa przewodnik Elastic na temat AI, jeśli system AI ujawni dane wrażliwe lub wypowie się w sposób niestosowny, skutki mogą obejmować grzywny regulacyjne i poważne szkody wizerunkowe, „wpływając na wynik finansowy.” Zespoły ds. zgodności potrzebują danych obserwowalności (np. pełnych zapisów rozmów i historii wersji modelu), by wykazać należytą staranność i prowadzić dochodzenia. Jeśli nie jesteś w stanie odpowiedzieć na pytanie „co, komu i dlaczego powiedział model?”, narażasz firmę na pozwy i sankcje.
5.2 Reputacja marki i zaufanie
Halucynacje i nieścisłości – szczególnie gdy są częste lub rażące – podważają zaufanie użytkowników do produktu. Wyobraź sobie AI w bazie wiedzy, które od czasu do czasu wymyśla informacje o Twoim produkcie – klienci szybko stracą zaufanie i mogą nawet zakwestionować wiarygodność Twojej marki. Albo asystent AI, który przypadkowo wypowiada się obraźliwie lub stronniczo – skutki PR-owe mogą być poważne. Bez obserwowalności takie incydenty mogą pozostać w ukryciu. Nie chcesz dowiedzieć się z viralowego tweeta, że Twój chatbot kogoś obraził. Proaktywne monitorowanie pozwala wychwytywać szkodliwe treści wewnętrznie, zanim eskalują. Umożliwia także raportowanie jakości działania AI (np. „99,5% odpowiedzi w tym tygodniu było zgodnych z marką i merytorycznych”), co może być przewagą konkurencyjną. Brak obserwowalności LLM to jak lot na ślepo – drobne błędy mogą urosnąć do rangi publicznych kryzysów.
5.3 Dezinformacja i błędne decyzje
Jeśli pracownicy lub klienci traktują LLM jako wiarygodnego asystenta, każdy niezauważony wzrost liczby błędów może prowadzić do złych decyzji. Nieobserwowany model może zacząć udzielać subtelnie błędnych rekomendacji (np. AI dla działu sprzedaży sugerujące nieprawidłowe ceny lub AI medyczne dające nieprecyzyjne rady dotyczące objawów). Takie błędy merytoryczne mogą rozprzestrzeniać się w organizacji lub wśród klientów, powodując realne konsekwencje. Dezinformacja może także prowadzić do odpowiedzialności prawnej, jeśli na podstawie błędnej odpowiedzi AI zostaną podjęte działania. Monitorując poprawność (poprzez wskaźniki halucynacji lub pętle informacji zwrotnej od użytkowników), organizacje ograniczają ryzyko rozprzestrzeniania się błędnych odpowiedzi. Innymi słowy, obserwowalność działa jak siatka bezpieczeństwa – wychwytując momenty, gdy wiedza lub spójność AI się pogarsza, zanim błędy wyrządzą szkody.
5.4 Niska efektywność operacyjna i ukryte koszty
LLM-y, które nie są monitorowane, mogą stać się nieefektywne lub kosztowne, zanim ktokolwiek to zauważy. Na przykład jeśli prompty stopniowo się wydłużają, a użytkownicy zadają coraz bardziej złożone pytania, zużycie tokenów na żądanie może gwałtownie wzrosnąć – a wraz z nim koszty API – bez wyraźnej widoczności. Albo model zacznie zawodzić przy konkretnych zadaniach, przez co pracownicy będą musieli poświęcać czas na weryfikację odpowiedzi (spadek produktywności). Brak monitorowania może też prowadzić do zbędnych obciążeń – np. różne zespoły mogą nieświadomie korzystać z tego samego modelu z podobnymi zapytaniami, marnując zasoby obliczeniowe. Dzięki właściwej obserwowalności możesz śledzić zużycie tokenów, wzorce użycia i wąskie gardła wydajnościowe, aby optymalizować efektywność. Brak monitorowania AI często oznacza marnowanie pieniędzy – czy to przez nieefektywne wykorzystanie zasobów, czy przez nadmiarowe koszty. W pewnym sensie obserwowalność sama się spłaca – wskazując możliwości optymalizacji (np. gdzie warto dodać cache albo zastąpić drogi model tańszym przy mniej wymagających zapytaniach).
5.5 Zatrzymana innowacja i niepowodzenia wdrożeniowe
Istnieje bardziej subtelne, ale istotne ryzyko: bez obserwowalności projekty AI mogą utknąć w martwym punkcie. Badania i raporty branżowe pokazują, że wiele inicjatyw AI/ML nie przechodzi z etapu pilotażowego do produkcyjnego, często z powodu braku zaufania i możliwości zarządzania. Jeśli deweloperzy i interesariusze nie potrafią wyjaśnić ani zdebugować działania AI, tracą zaufanie i mogą porzucić projekt (efekt „czarnej skrzynki”). W przedsiębiorstwach oznacza to zmarnowaną inwestycję w rozwój AI. Słaba obserwowalność może więc prowadzić bezpośrednio do anulowania projektów lub porzucenia funkcji opartych na AI. Z drugiej strony, dobre monitorowanie i śledzenie dają zespołom pewność, że mogą skalować użycie AI, ponieważ wiedzą, że są w stanie szybko wychwycić problemy i stale ulepszać system. Przekształca to AI z ryzykownego eksperymentu w stabilny element operacyjny. Jak zauważyli analitycy Splunk, brak obserwowalności LLM może mieć poważne konsekwencje – to nie luksus, to konieczność konkurencyjna.
Podsumowując, ignorowanie obserwowalności LLM to ryzyko dla całej organizacji. Może prowadzić do naruszeń zgodności, kryzysów wizerunkowych, błędnych decyzji, niekontrolowanych kosztów, a nawet do upadku projektów AI. Z kolei solidna obserwowalność minimalizuje te zagrożenia dzięki zapewnieniu przejrzystości i kontroli. Nie wdrażałbyś nowego mikrousługowego komponentu bez logów i monitoringu – to samo dotyczy modeli AI, a może nawet bardziej, biorąc pod uwagę ich nieprzewidywalność.
6. Jak monitoring poprawia zaufanie, ROI i zwinność
Na szczęście są też dobre wiadomości: dobrze wdrożona obserwowalność LLM nie tylko zapobiega problemom – przynosi też konkretne korzyści biznesowe. Monitorując jakość i bezpieczeństwo odpowiedzi AI, organizacje mogą zwiększyć zaufanie użytkowników, zmaksymalizować zwrot z inwestycji w AI i przyspieszyć tempo innowacji.
- Wzmacnianie zaufania i adopcji: Użytkownicy (zarówno pracownicy, jak i klienci) muszą ufać Twojemu narzędziu AI, aby z niego korzystać. Za każdym razem, gdy model udziela trafnej odpowiedzi, zaufanie rośnie; każdy błąd je podważa. Monitorując jakość odpowiedzi na bieżąco, możesz wykrywać i poprawiać problemy, zanim staną się powszechne. Dzięki temu AI działa bardziej spójnie i przewidywalnie – co użytkownicy zauważają. Jeśli zauważysz, że AI gorzej radzi sobie z pewnym typem zapytań, możesz je poprawić (np. poprzez fine-tuning lub dodanie fallbacku). Kolejne pytania z tej kategorii będą obsługiwane lepiej, co wzmocni zaufanie. Z czasem dobrze monitorowany system AI utrzymuje wysoki poziom zaufania, co przekłada się na realne wykorzystanie. To kluczowe dla ROI – AI, którego pracownicy nie używają, bo „często się myli”, nie przynosi wartości. Monitoring to sposób na dotrzymywanie obietnic składanych użytkownikom. Można to porównać do kontroli jakości w produkcji – upewniasz się, że „produkt” (odpowiedzi AI) stale spełnia określone standardy, budując zaufanie do „marki” Twojego AI.
- Ochrona i zwiększanie ROI: Wdrażanie LLM-ów (zwłaszcza dużych modeli przez API) wiąże się z kosztami. Każdy wygenerowany token kosztuje, a każdy błąd też (czas wsparcia, odpływ klientów itd.). Obserwowalność pozwala maksymalizować zwrot z inwestycji poprzez ograniczanie strat i zwiększanie efektów. Możesz na przykład zauważyć, że wiele tokenów jest zużywanych na pytania, które mógłby obsłużyć prostszy model lub cache – dzięki czemu obniżysz koszty. Albo logi pokażą, że użytkownicy często zadają pytania pomocnicze – co oznacza, że początkowa odpowiedź była niejasna – poprawa prompta może zmniejszyć liczbę zapytań i poprawić UX. Wydajność i kontrola kosztów przekładają się bezpośrednio na ROI i są możliwe dzięki obserwowalności. Co więcej, śledząc metryki biznesowe (np. konwersję lub ukończenie zadań z pomocą AI), możesz pokazać związek między jakością AI a wartością biznesową. Jeśli dokładność modelu rośnie, a równolegle poprawia się wskaźnik satysfakcji klienta – to dowód na efektywność inwestycji. Krótko mówiąc, dane z obserwowalności pozwalają na ciągłą optymalizację wartości systemu AI.
- Szybsze iteracje i innowacje: Jedna z mniej oczywistych, ale bardzo ważnych zalet bogatej obserwowalności to możliwość szybkiego udoskonalania systemu. Gdy widzisz dokładnie, dlaczego model zachował się tak, a nie inaczej (dzięki trace’om) i możesz mierzyć efekty zmian (przez metryki jakości), tworzysz pętlę ciągłego doskonalenia. Zespoły mogą przetestować nowy prompt lub wersję modelu i natychmiast zaobserwować zmiany – czy liczba halucynacji spadła? Czy czas odpowiedzi się poprawił? – i dalej iterować. Taki cykl rozwoju jest znacznie szybszy niż praca bez wglądu (gdzie po wdrożeniu można tylko „mieć nadzieję”). Monitoring ułatwia także testy A/B czy stopniowe wdrożenia nowych funkcji AI, ponieważ masz dane porównawcze. Zgodnie z najlepszymi praktykami, instrumentacja i obserwowalność powinny być obecne od pierwszego dnia, aby każda iteracja przynosiła wiedzę. Firmy traktujące obserwowalność AI jako priorytet zyskują przewagę nad konkurencją, która błądzi po omacku. Jak trafnie ujął to raport Splunk, obserwowalność LLM jest niezbędna w produkcyjnych systemach AI – „buduje zaufanie, trzyma koszty pod kontrolą i przyspiesza rozwój.” Każda iteracja, wychwycona dzięki obserwowalności, przesuwa zespół od reaktywności w stronę proaktywnego ulepszania AI. Efekt końcowy to bardziej solidny system AI, dostarczany szybciej.
Najprościej mówiąc, monitorowanie jakości i bezpieczeństwa systemu AI to jak prowadzenie analityki procesu biznesowego. Pozwala zarządzać i ulepszać ten proces. Dzięki obserwowalności LLM nie musisz się domyślać, czy AI pomaga Twojej firmie – masz dane, by to udowodnić, i narzędzia, by to poprawić. To zwiększa zaufanie interesariuszy (zarządy uwielbiają metryki pokazujące, że AI jest pod kontrolą i przynosi korzyści) i toruje drogę do skalowania AI na kolejne obszary. Gdy ludzie wiedzą, że AI jest ściśle monitorowane i optymalizowane, są bardziej skłonni inwestować w jego szerokie wdrażanie. Dobra obserwowalność może więc przekształcić ostrożny pilotaż w skuteczne wdrożenie AI na poziomie całej firmy, z poparciem zarówno użytkowników, jak i kadry zarządzającej.
7. Metryki i alerty: Przykłady z praktyki
Jak w praktyce wyglądają metryki i alerty dotyczące obserwowalności LLM? Oto kilka konkretnych przykładów, które może wdrożyć firma:
- Alert o wzroście halucynacji: Załóżmy, że dla każdej odpowiedzi definiujesz „wskaźnik halucynacji” (np. na podstawie automatycznego porównania odpowiedzi AI z bazą wiedzy lub oceny faktograficznej przez inne LLM). Możesz śledzić średni poziom halucynacji w czasie. Jeśli w danym dniu lub godzinie ten wskaźnik przekroczy ustalony próg – co sugeruje, że model generuje nietypowo niedokładne informacje – uruchamiany jest alert. Przykład: „Alert: wskaźnik halucynacji przekroczył 5% w ostatniej godzinie (próg: 2%)”. Taki komunikat pozwala zespołowi natychmiast zbadać sytuację – może ostatnia aktualizacja modelu spowodowała błędy, a może model gubi się przy konkretnym temacie. Przykład z praktyki: zespoły wdrażają pipeline’y, które po wykryciu zbyt dużych odchyleń od źródeł wiedzy powiadamiają inżyniera. Platformy jak Galileo pozwalają ustawiać alerty przy zmianach w dynamice rozmów – np. wzroście halucynacji lub toksyczności ponad normę.
- Alert z filtra toksyczności: Wiele firm filtruje odpowiedzi AI pod kątem toksyczności (np. używając API moderacyjnego OpenAI lub własnego modelu). Warto śledzić, jak często filtr się aktywuje. Przykładowa metryka: „% odpowiedzi oznaczonych jako toksyczne”. Jeśli ten odsetek gwałtownie rośnie (np. zwykle 0,1%, a nagle 1%), coś jest nie tak – może użytkownicy zadają wrażliwe pytania, albo model zmienił zachowanie. Alert: „Alerty polityki treści wzrosły dziesięciokrotnie dzisiaj”, co skłania do przeglądu zapytań i odpowiedzi. Takie monitorowanie pozwala wcześnie wykryć problemy PR lub naruszenia zasad. Lepiej samodzielnie zauważyć, że AI reaguje zbyt ostro, niż dowiedzieć się o tym z virala na Twitterze. Proaktywne alerty dają tę szansę.
- Naruszenie SLA dotyczącego opóźnień: Pisaliśmy o metryce Time to First Token (TTFT). Załóżmy, że masz wewnętrzne SLA, zgodnie z którym 95% zapytań użytkowników powinno uzyskać odpowiedź w ciągu 2 sekund. Możesz monitorować p95 opóźnienia i ustawić alert, jeśli przekroczy 2s przez więcej niż 5 minut. Przykład z wdrożenia OpenShift AI: monitorują TTFT i mają wykresy w Grafanie pokazujące p95 i p99 TTFT – gdy wartości rosną, sygnalizuje to spadek wydajności. Alert: „Spadek wydajności: 95. percentyl czasu odpowiedzi wynosi 2500 ms (próg: 2000 ms).”. To sygnał dla zespołu operacyjnego, by sprawdzić, czy nowa wersja modelu działa wolniej, czy może zwiększyło się obciążenie. Utrzymanie szybkiej odpowiedzi to klucz do zaangażowania użytkownika, więc te alerty mają bezpośredni wpływ na UX.
- Wykrywanie anomalii w promptach: Bardziej zaawansowany przykład to analiza anomalii w zapytaniach kierowanych do AI. To ważne dla bezpieczeństwa – chcesz wiedzieć, czy ktoś nie próbuje ataku prompt injection. Firmy mogą wdrażać detektory analizujące prompt pod kątem podejrzanych wzorców (np. „zignoruj wszystkie wcześniejsze instrukcje i…”). Gdy zapytanie znacząco odbiega od normy, system je oznacza. Alert może brzmieć: „Wykryto nietypowy prompt od użytkownika X – możliwy atak prompt injection.” Może to też zintegrować się z systemami bezpieczeństwa. Dane z obserwowalności mogą zasilać mechanizmy obronne: np. prompt uznany za złośliwy może zostać automatycznie odrzucony i zarejestrowany. Dla firmy oznacza to, że ataki lub nadużycia nie pozostają niezauważone. Jak zauważono w jednym z przewodników, monitoring może pomóc „wykrywać próby jailbreaku, zatruwanie kontekstu i inne ataki, zanim dotrą do użytkowników.”
- Trendy dryfu i spadku dokładności: Warto też śledzić trendy jakości w dłuższej perspektywie. Jeśli masz „wskaźnik dokładności” z okresowych ocen lub opinii użytkowników, możesz go wykreślić i ustawić alert trendowy. „Alert: dokładność modelu spadła o 10% w porównaniu z zeszłym miesiącem.”. Może to wynikać z dryfu danych (świat się zmienił, a model nie), albo z błędu w szablonie prompta. Przykład z e-commerce: AI asystent zakupowy – śledzisz wskaźnik „skutecznych rekomendacji” (czy użytkownicy klikają lub akceptują sugestie). Gdy ten wskaźnik spada, alert trafia do product managerów – może rekomendacje stały się mniej trafne, bo zmienił się asortyment i trzeba przeuczyć model. Podobnie można monitorować dryf embeddingów (jeśli używasz wektorowego wyszukiwania) – jeśli nowe dane różnią się znacząco od wcześniejszych, może to sygnalizować potrzebę aktualizacji. Takie alerty pomagają utrzymać skuteczność AI w dłuższym czasie.
- Wzrost kosztów lub użycia: Praktyczna metryka to monitoring kosztów i zużycia. Jeśli masz miesięczny budżet na AI, warto śledzić zużycie tokenów (które często przekłada się bezpośrednio na koszty API) lub liczbę wywołań modelu. Jeśli nagle jeden użytkownik lub funkcja zużywa 5x więcej niż zwykle, alert typu „Alert: dzisiejsze zużycie LLM wynosi 300% normy – możliwe nadużycie lub zapętlenie” może uchronić Cię przed stratami. Przykład z branży: błąd spowodował, że agent AI wywoływał sam siebie w pętli, generując ogromny rachunek – monitoring liczby wywołań pozwoliłby wykryć pętlę po kilku minutach. Zwłaszcza gdy LLM działa przez API, wzrosty zużycia mogą oznaczać sukces (wzrost adopcji – trzeba zwiększyć pojemność) lub problem (np. zautomatyzowany atak lub błąd). Tak czy inaczej, alerty są niezbędne.
Te przykłady pokazują, że obserwowalność LLM to nie tylko pasywne monitorowanie, ale aktywna bariera ochronna. Definiując odpowiednie metryki i progi alarmowe, zasadniczo programujesz system, by sam siebie obserwował i “krzyczał”, gdy coś wygląda podejrzanie. Ten system wczesnego ostrzegania może zapobiec przekształceniu drobnych problemów w poważne incydenty. Daje też zespołowi konkretne, ilościowe sygnały do zbadania, zamiast niejasnych zgłoszeń w stylu „AI ostatnio dziwnie działa”. W środowisku korporacyjnym takie alerty i pulpity nawigacyjne są zwykle dostępne nie tylko dla inżynierów, ale także dla product managerów i oficerów ds. ryzyka lub zgodności (np. w przypadku naruszeń treści). Rezultatem jest zdolność zespołów międzyfunkcyjnych do szybkiego reagowania na problemy z AI, co utrzymuje płynność działania i wiarygodność systemów w produkcji.

8. Build vs. Buy: Własna obserwowalność czy gotowe rozwiązania?
Przy wdrażaniu obserwowalności LLM pojawia się strategiczne pytanie: czy budować te możliwości wewnętrznie z użyciem narzędzi open source, czy korzystać z gotowych platform i usług? Odpowiedź często brzmi: połączenie obu podejść, w zależności od zasobów i potrzeb. Przyjrzyjmy się opcjom.
8.1 Własna (DIY) obserwowalność
To podejście polega na wykorzystaniu istniejącej infrastruktury logowania i monitorowania oraz ewentualnie narzędzi open source do instrumentacji aplikacji opartych o LLM. Przykładowo, programiści mogą dodać logikę rejestrującą prompty i odpowiedzi, wysyłać je do systemu logowania (np. Splunk, Elastic) i emitować własne metryki do Prometheusa – np. liczbę tokenów czy wskaźniki błędów. Można też wykorzystać biblioteki OpenTelemetry do generowania standardowych śladów (traces) dla każdego żądania AI i eksportować je do wybranego backendu monitorowania. Zaletą podejścia wewnętrznego jest pełna kontrola nad danymi (istotne w wrażliwych środowiskach) oraz elastyczność w definiowaniu tego, co śledzić. Nie jesteś ograniczony przez schematy dostawcy – możesz logować każdy detal, jeśli chcesz.
Coraz więcej dostępnych jest też narzędzi open-source, które to wspierają, np. Langfuse (open-source’owe narzędzie do logowania śladów LLM) czy Phoenix (biblioteka Arize do obserwowalności AI), które możesz hostować samodzielnie. Minusem budowania własnych rozwiązań jest potrzeba posiadania zespołu inżynierów z doświadczeniem w AI i systemach logowania. Trzeba zintegrować różne elementy, zbudować pulpity, zdefiniować alerty i utrzymywać całą infrastrukturę. Dla organizacji z silnymi zespołami devops i wysokimi wymaganiami w zakresie zgodności z przepisami (np. banki, placówki medyczne), podejście własne często jest preferowane. Umożliwia też wykorzystanie istniejących inwestycji w monitorowanie IT, poszerzając je o sygnały z AI.
8.2 Gotowe rozwiązania i platformy dedykowane AI
Wiele firm oferuje dziś obserwowalność AI jako usługę lub gotowy produkt, co może znacząco przyspieszyć wdrożenie. Takie platformy zawierają gotowe funkcje, jak specjalistyczne pulpity do analizy promptów/odpowiedzi, algorytmy wykrywania dryfu, wbudowane mechanizmy oceny i wiele innych. Przykłady często wymieniane to:
- OpenAI Evals: To open-source’owy framework (od OpenAI) do systematycznej oceny wyników modelu. Choć nie jest to narzędzie do ciągłego monitorowania, stanowi cenny element ekosystemu. Pozwala zdefiniować testy ewaluacyjne (evals) – np. porównujące odpowiedzi z bazą wiedzy lub sprawdzające zgodność ze stylem – i uruchamiać je okresowo lub przy nowych wersjach modelu. Można to porównać do testów jednostkowych/integracyjnych dla zachowania AI. Evals nie służy do monitorowania każdej odpowiedzi w czasie rzeczywistym, ale do okresowego audytu jakości modelu. Przydaje się szczególnie przy zmianie modelu: można uruchomić zestaw evals, by upewnić się, że nowa wersja nie jest gorsza pod względem faktów czy formatu. Zespoły QA lub centra kompetencji AI mogą utrzymywać własne pakiety testów. OpenAI udostępnia dashboard i API do evals (jeśli korzystasz z ich platformy), ale można też uruchomić wersję open source lokalnie. Decyzja sprowadza się do tego, czy chcesz inwestować w tworzenie własnych testów (co opłaca się przy krytycznych zastosowaniach), czy raczej polegać na bardziej automatycznym monitoringu na co dzień. W praktyce wiele firm łączy oba podejścia: monitoring na żywo wykrywa bieżące anomalie, a frameworki takie jak Evals służą do głębszej, okresowej oceny jakości modelu względem benchmarków.
- Weights & Biases (W&B): W&B to dobrze znane narzędzie do śledzenia eksperymentów ML, które zostało rozszerzone o wsparcie dla aplikacji opartych na LLM. Z W&B możesz logować prompty, konfiguracje modeli i wyniki jako część eksperymentów lub wdrożeń produkcyjnych. Platforma oferuje narzędzia wizualizacji do porównywania wersji modeli oraz zarządzania promptami. Na przykład, W&B pozwala śledzić liczbę tokenów, opóźnienia, a także tworzyć wykresy uwagi (attention) lub aktywacji, powiązując je z konkretnymi wersjami modeli czy wycinkami zbioru danych. Zaletą W&B jest łatwa integracja z cyklem rozwoju modeli – deweloperzy już go używają do trenowania i strojenia modeli, więc rozszerzenie go na monitoring produkcyjny jest naturalnym krokiem. W&B może pełnić rolę centralnego huba do śledzenia metryk zarówno z treningu, jak i produkcji. Trzeba jednak zaznaczyć, że to rozwiązanie hostowane (choć dane mogą pozostać prywatne) i bardziej nastawione na deweloperów niż na dashboardy biznesowe. Jeśli chcesz, by narzędzie było także użyteczne dla właścicieli produktów czy inżynierów operacyjnych, warto połączyć W&B z innymi rozwiązaniami. W&B doskonale sprawdza się w szybkiej iteracji i śledzeniu eksperymentów, choć mniej w czasie rzeczywistym (choć da się skonfigurować alerty przez API lub połączyć je z np. PagerDuty).
- Arize (platforma obserwowalności AI): Arize to platforma zaprojektowana specjalnie do monitorowania modeli ML, w tym LLM-ów. Oferuje pełny pakiet funkcji: wykrywanie dryfu danych, monitoring biasu, analiza osadzeń (embeddingów) i śledzenie trace’ów. Jedną z mocnych stron Arize jest skupienie na produkcji – może ciągle przyjmować predykcje i wyniki z modeli i analizować je pod kątem problemów. Dla LLM-ów Arize wprowadziło funkcje takie jak śledzenie LLM (LLM tracing) (rejestrowanie sekwencji promptów i odpowiedzi) oraz ocenę przy użyciu „LLM-as-a-Judge” (czyli ocenianie odpowiedzi przez inny model). Platforma oferuje gotowe widgety dashboardowe do takich metryk jak współczynnik halucynacji, wskaźnik błędów promptów, rozkład opóźnień itp. Istotne jest też to, że Arize opiera się na otwartych standardach jak OpenTelemetry, więc możesz zainstrumentować aplikację i przesłać dane trace w standardowym formacie, a Arize je zinterpretuje. Jeśli nie chcesz samodzielnie budować analityki embeddingów czy dryfu, Arize dostarcza te funkcje gotowe – np. automatycznie pokaże, jeśli dzisiejsza dystrybucja promptów znacząco odbiega od tej sprzed tygodnia (co może tłumaczyć dziwne zachowanie modelu). Dodatkowym atutem jest możliwość ustawienia monitorów w Arize, które powiadomią Cię, jeśli np. dokładność spadnie dla danego segmentu danych lub wzrośnie częstość konkretnego typu błędów (np. odmowy odpowiedzi). To w zasadzie wieża kontroli AI. Minusem są koszty i kwestie przesyłania danych do zewnętrznej usługi. Arize podkreśla gotowość na potrzeby przedsiębiorstw (oferuje neutralność dostawcy i możliwość wdrożenia on-premises), co może złagodzić te obawy. Jeśli Twój zespół jest mały lub zależy Ci na szybkim wdrożeniu, taka platforma może oszczędzić mnóstwo czasu, oferując gotowe rozwiązanie obserwowalności AI.
Poza tym są też inne zarządzane narzędzia i start-upy (np. TruEra, Mona, Galileo), które koncentrują się na monitorowaniu jakości AI – niektóre z nich specjalizują się w NLP/LLM. Istnieją też biblioteki open-source, takie jak Trulens lub moduły debugowania Langchain, które mogą stanowić element wewnętrznego rozwiązania.

Kiedy wybrać które podejście? Heurystyka: jeśli Twoje użycie AI jest już na dużą skalę lub wiąże się z dużym ryzykiem (np. systemy użytkowe w branży regulowanej), oparcie się na sprawdzonej platformie może przyspieszyć zdolność do jego zarządzania. Takie platformy mają już zaimplementowane dobre praktyki i będą szybciej reagować na nowe zagrożenia (jak najnowsze techniki prompt injection), niż zespół wewnętrzny. Z drugiej strony, jeśli przypadek użycia jest bardzo specyficzny lub masz rygorystyczne wymagania prywatności danych, budowanie wewnętrzne oparte na otwartych narzędziach może być lepsze. Niektóre firmy zaczynają in-house, a później w miarę rozwoju integrują rozwiązania vendorowe dla bardziej zaawansowanej analityki.
W wielu przypadkach sprawdza się podejście hybrydowe: instrumentacja w standardzie OpenTelemetry umożliwia przesyłanie danych do wielu miejsc. Możesz jednocześnie wysyłać trace’y do własnego systemu logowania i do platformy zewnętrznej. To pozwala uniknąć zależności od jednego dostawcy i zwiększa elastyczność. Przykładowo, surowe logi mogą trafiać do Splunka na potrzeby audytu długoterminowego, a zagregowane metryki i ewaluacje – do specjalistycznego dashboardu dla zespołu AI.
Wybór zależy też od dojrzałości zespołu. Jeśli masz silny zespół MLOps lub devops, zainteresowany budowaniem takich funkcji – ścieżka wewnętrzna może być opłacalna i rozwijająca. Jeśli nie – korzystanie z zarządzanej usługi (czyli de facto outsourcowanie analityki i interfejsu) może być warte inwestycji, by dobrze rozpocząć monitorowanie AI.
Niezależnie od podejścia, ważne, by plan obserwowalności powstał już na wczesnym etapie projektu LLM. Nie czekaj na pierwszy incydent, by naprędce tworzyć logowanie. Jak powiedziałby każdy dobry konsultant: traktuj obserwowalność jako wymaganie podstawowe, a nie luksusowy dodatek. Znacznie łatwiej ją wdrożyć od początku niż dobudowywać po wdrożeniu AI, które już zaczęło działać (i może sprawiać problemy).







