Czy wiesz, że GPT-5 mógł być trenowany na transkrypcjach Twoich ulubionych filmów z YouTube, wątkach z Reddita, które kiedyś polubiłeś, a nawet na kodzie, który wrzuciłeś na GitHuba? Wraz ze wzrostem możliwości modeli językowych rośnie także ich apetyt na ogromne i zróżnicowane zbiory danych — a razem z nim pojawiają się pytania etyczne. Co dokładnie trafiło do zasobów wiedzy GPT-5? I jak to się ma do danych, które zasilały jego poprzedników, takich jak GPT-3 czy GPT-4? W tym artykule przyglądamy się znanym (i mniej znanym) faktom na temat danych treningowych GPT-5 i analizujemy rosnącą kontrowersję wokół kwestii przejrzystości, zgody i sprawiedliwości w szkoleniu sztucznej inteligencji. Prześledźmy, jak zmieniały się źródła danych i podejście OpenAI do ich ujawniania.
1. Jak zmieniały się dane treningowe od GPT-1 do GPT-5?
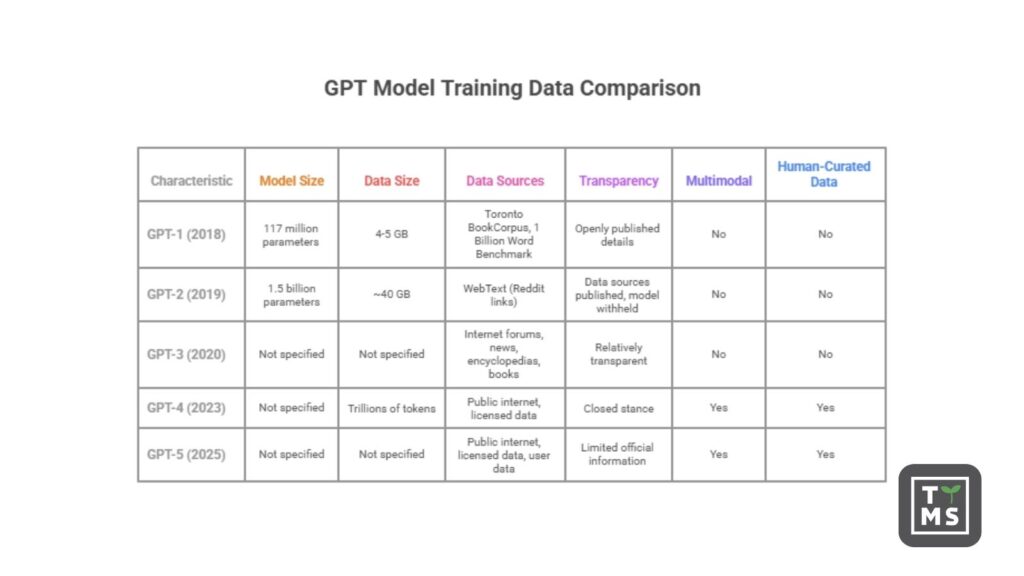
1.1 Na jakich danych uczono pierwszego GPT w 2018 roku?
GPT-1 (2018): Oryginalny Generative Pre-Trained Transformer (GPT-1) był jak na dzisiejsze standardy modelem niewielkim (117 milionów parametrów) i został wytrenowany na mieszance tekstów książkowych i internetowych. Zgodnie z publikacją OpenAI z 2018 roku, GPT-1 przeszedł nienadzorowane treningi na dwóch korpusach: Toronto BookCorpus (~800 milionów słów z książek fabularnych) oraz 1 Billion Word Benchmark (zbiór ~1 miliarda słów pochodzących z artykułów prasowych). Dało to modelowi solidną bazę w zakresie języka pisanego, zwłaszcza dłuższych form narracyjnych. Zastosowanie opublikowanych książek zapewniło różnorodność stylów literackich, choć zauważono, że korpus zawierał wiele romansów, co mogło wprowadzać pewne ukierunkowane uprzedzenia gatunkowe. Dane treningowe GPT-1 ważyły stosunkowo niewiele — około 4–5 GB tekstu — a OpenAI udostępniło te szczegóły publicznie w pracy badawczej, ustanawiając tym samym początkowy standard przejrzystości.
1.2 Jakie dane z internetu napędzały GPT-2?
GPT-2 (2019): Z liczbą 1,5 miliarda parametrów GPT-2 znacząco zwiększył zarówno rozmiar modelu, jak i skalę danych treningowych. OpenAI stworzyło własny zbiór danych o nazwie WebText, zbierając treści z internetu — konkretnie ze stron internetowych, do których linkowano na Reddicie i które otrzymały co najmniej 3 głosy w górę. W sumie zebrano około 8 milionów stron wysokiej jakości, co dało ~40 GB tekstu pochodzącego z różnych źródeł (z wyłączeniem Wikipedii). To oznaczało dziesięciokrotny wzrost objętości danych w porównaniu z GPT-1. Strategia WebText zakładała, że system upvote’ów Reddita promuje treści ciekawe lub użyteczne, co pozwalało pozyskać naturalne przykłady wielu różnych zastosowań językowych. GPT-2 był trenowany po prostu na przewidywaniu kolejnych słów w tym korpusie — zawierającym artykuły prasowe, blogi, literaturę i inne formy tekstu.
Warto zauważyć, że OpenAI początkowo wstrzymało się z udostępnieniem pełnej wersji GPT-2 w lutym 2019 roku, powołując się na obawy, że model mógłby zostać wykorzystany do generowania fałszywych informacji lub spamu ze względu na zaskakująco dobrą jakość wyników. (Modele GPT-2 udostępniano stopniowo w kolejnych miesiącach.) Mimo to, sam opis zbioru treningowego został opublikowany: „40 GB tekstu z Internetu” z 8 milionów stron. Ta otwartość w zakresie źródeł danych (mimo tymczasowego zastrzeżenia samych wag modelu) pokazywała gotowość OpenAI do transparentnego informowania o tym, na czym model był trenowany — nawet jeśli już wtedy zaczynała się debata na temat etycznych skutków udostępniania potężnych modeli językowych.
1.3 Skąd pochodziły dane treningowe GPT-3 i jak je przefiltrowano?
GPT-3 (2020): Wydanie GPT-3 oznaczało nowy skok w skali: 175 miliardów parametrów i setki miliardów tokenów danych treningowych. Artykuł OpenAI zatytułowany „Language Models are Few-Shot Learners” szczegółowo opisał złożony zestaw danych. GPT-3 został wytrenowany na ogromnym korpusie (~570 GB przefiltrowanego tekstu, łącznie ok. 500 miliardów tokenów) pochodzącym z pięciu głównych źródeł:
- Common Crawl (filtrowany): Ogromna kolekcja stron internetowych zebranych w latach 2016–2019, po intensywnej filtracji jakościowej, dostarczająca ok. 410 miliardów tokenów (około 60% danych GPT-3). OpenAI przefiltrowało Common Crawl przy użyciu klasyfikatora, który wybierał strony podobne do wysokiej jakości korpusów referencyjnych, oraz zastosowało tzw. fuzzy deduplication, aby usunąć duplikaty. W efekcie powstał „oczyszczony” zbiór stron obejmujący miliony witryn (głównie w języku angielskim, z przewagą treści z USA). Dzięki temu GPT-3 zdobyło szeroką wiedzę o tekście internetowym, a filtracja miała na celu pominięcie stron niskiej jakości lub bezsensownych.
- WebText2: Rozszerzenie koncepcji WebText z GPT-2 – OpenAI zebrało linki z Reddita przez dłuższy okres niż w przypadku oryginalnego WebText, uzyskując około 19 miliardów tokenów (22% danych treningowych). Był to w zasadzie „wyselekcjonowany internetowy materiał”, wybierany przez użytkowników Reddita, obejmujący tematy, które wzbudzały zainteresowanie online, i miał większą wagę w procesie uczenia ze względu na wyższą jakość treści.
- Books1 i Books2: Dwa duże zbiory książek (opisane w artykule tylko ogólnie) o łącznej liczbie 67 miliardów tokenów. Books1 zawierał ok. 12 miliardów tokenów, a Books2 ok. 55 miliardów, co dawało po ok. 8% udziału w całości. OpenAI nie ujawniło publicznie, jakie to dokładnie zbiory, ale badacze przypuszczają, że Books1 to zbiór klasyki w domenie publicznej (np. Project Gutenberg), a Books2 to większy zestaw książek online (być może pochodzący z tzw. „shadow libraries”). Włączenie tych dwóch zestawów pozwoliło modelowi uczyć się na dłuższych, dobrze zredagowanych tekstach, takich jak powieści i literatura faktu, uzupełniających bardziej potoczne treści z internetu. Co ciekawe, OpenAI zdecydowało się nadpróbkować mniejszy zbiór Books1 (ok. 1,9 epoki), a większy Books2 tylko częściowo (0,43 epoki), co sugeruje, że bardziej ceniono wyższą jakość lub klasyczny charakter literatury w Books1 niż ilość danych z Books2.
- Wikipedia w języku angielskim: Fragment Wikipedii zawierający ok. 3 miliardy tokenów (ok. 3% całości). Wikipedia to dobrze ustrukturyzowany, faktograficzny tekst, więc jej włączenie pomogło GPT-3 w rozwijaniu wiedzy ogólnej i spójności faktów. Mimo że stanowiła niewielką część danych, jej wysoka jakość czyniła ją wartościowym elementem zbioru.
Podsumowując, dane treningowe GPT-3 były niezwykle zróżnicowane: fora internetowe, serwisy informacyjne, encyklopedie i książki. Ta różnorodność umożliwiła modelowi imponujące zdolności few-shot learning (uczenia z niewielkiej liczby przykładów), ale jednocześnie oznaczała, że GPT-3 przyswoiło również wiele niedoskonałości obecnych w internecie. OpenAI zachowało wówczas względną przejrzystość w kwestii źródeł danych, przedstawiając ich udział w całości i wyjaśniając, że dane wyższej jakości były nadpróbkowane w celu poprawy wyników. W artykule opisano także działania mające na celu ograniczenie problemów z danymi (np. usuwanie duplikatów i eliminowanie fragmentów z zestawów testowych, które mogłyby „zanieczyścić” wyniki). Na tym etapie przejrzystość była wciąż priorytetem – społeczność naukowa wiedziała, co wchodziło w skład danych GPT-3, nawet jeśli nie znała dokładnych list stron internetowych.
- WebText2: Rozszerzenie koncepcji WebText znanej z GPT-2 — OpenAI zebrało linki z Reddita z dłuższego okresu niż w przypadku oryginalnego WebText, uzyskując około 19 miliardów tokenów (22% danych treningowych). Była to w praktyce starannie dobrana treść internetowa wybrana przez użytkowników Reddita, prawdopodobnie dotycząca tematów, które wzbudzały duże zainteresowanie w sieci. Ze względu na wyższą jakość tej treści, została ona objęta wyższą wagą próbkowania w trakcie treningu.
- Books1 i Books2: Dwa duże zbiory książek (opisane w publikacji jedynie ogólnie), łącznie obejmujące 67 miliardów tokenów. Books1 zawierał około 12 miliardów tokenów, a Books2 około 55 miliardów — każdy z nich stanowił około 8% miksu treningowego GPT-3. OpenAI nie podało publicznie, czym dokładnie były te zbiory, ale badacze przypuszczają, że Books1 to kolekcja klasyki z domeny publicznej (np. Project Gutenberg), a Books2 to większy zbiór książek online (być może pochodzący z tzw. shadow libraries). Włączenie dwóch korpusów książek sprawiło, że GPT-3 uczył się na dłuższych, starannie zredagowanych tekstach, takich jak powieści czy literatura faktu, co dobrze uzupełniało bardziej swobodne treści z internetu. Co ciekawe, OpenAI zdecydowało się nadpróbkować mniejszy zbiór Books1 (około 1,9 epoki), podczas gdy większy Books2 był próbkowany rzadziej (0,43 epoki). Wskazuje to, że wyżej oceniano jakość — lub klasyczną wartość — Books1 niż ilość danych w Books2.
- Wikipedia (angielska): Fragment anglojęzycznej Wikipedii o objętości około 3 miliardów tokenów (około 3% całości). Wikipedia to dobrze uporządkowany, faktograficzny tekst, więc jej uwzględnienie pomagało GPT-3 zdobyć wiedzę ogólną i utrzymać spójność faktów. Mimo że stanowiła niewielką część zbioru danych, jej wysoka jakość czyniła ją cennym komponentem.
Podsumowując, dane treningowe GPT-3 były niezwykle zróżnicowane: fora internetowe, serwisy informacyjne, encyklopedie i książki. Ta różnorodność umożliwiła modelowi imponującą zdolność few-shot learning (uczenia się na podstawie kilku przykładów), ale oznaczała też, że GPT-3 przyswoił wiele niedoskonałości obecnych w internecie. OpenAI było stosunkowo transparentne w kwestii tych źródeł — w publikacji opisano podział liczby tokenów i zaznaczono, że źródła wyższej jakości były nadpróbkowywane, aby poprawić skuteczność. W pracy omówiono również kroki podjęte w celu ograniczenia problemów z danymi (takich jak filtrowanie duplikatów czy usuwanie potencjalnie skażonych przykładów z zestawów ewaluacyjnych). Na tym etapie przejrzystość wciąż była priorytetem — społeczność badawcza wiedziała, z czego składał się korpus GPT-3, nawet jeśli nie publikowano pełnej listy stron.
1.4 Dlaczego OpenAI przestało ujawniać szczegóły w GPT-4?
GPT-4 (2023): Wraz z premierą GPT-4, OpenAI obrało znacznie bardziej zamkniętą strategię. GPT-4 to model multimodalny (akceptujący tekst i obrazy), który przyniósł wyraźny postęp względem GPT-3. Jednak w oficjalnym raporcie technicznym OpenAI nie ujawniło szczegółów dotyczących danych treningowych GPT-4. Wprost zaznaczono tam: „Z uwagi na konkurencyjny krajobraz i implikacje bezpieczeństwa związane z dużymi modelami, ten raport nie zawiera żadnych dodatkowych informacji o architekturze (w tym rozmiarze modelu), sprzęcie, mocy obliczeniowej, konstrukcji zbioru danych ani metodzie trenowania.” Innymi słowy, w przeciwieństwie do wcześniejszych modeli, twórcy GPT-4 nie opublikowali listy źródeł danych ani ich wielkości.
Pojawiły się jednak ogólne wskazówki. OpenAI potwierdziło, że GPT-4 był trenowany na miksie danych publicznie dostępnych (np. tekstów z internetu) oraz „danych licencjonowanych od zewnętrznych dostawców”. To oznacza najprawdopodobniej, że wykorzystano dużą część internetu (być może zaktualizowaną wersję Common Crawl lub podobny korpus stron), a także dodatkowe, starannie dobrane źródła zakupione lub pozyskane na licencji. Mogły to być np. komercyjne bazy danych akademickich, serwisy informacyjne, prywatne zbiory książek lub repozytoria kodu — choć OpenAI nie podało szczegółów. Co istotne, uważa się, że GPT-4 trenował intensywnie na zbiorach kodu i treści technicznych, co tłumaczy jego bardzo dobre umiejętności programistyczne. (Współpraca OpenAI z Microsoftem prawdopodobnie umożliwiła dostęp do danych z GitHuba — przypomnijmy, że model Copilot był wcześniejszym przykładem uczenia się na publicznym kodzie.)
Na podstawie znanej daty cutoffu wiedzy GPT-4 (wrzesień 2021), można też wnioskować, że dane zebrane do treningu obejmowały okres do tego właśnie momentu. Dodatkowo, ze względu na komponent wizualny GPT-4, model musiał uczyć się na parach obraz–tekst; OpenAI potwierdziło, że uwzględniono dane obrazowe, co czyni GPT-4 pełnoprawnym modelem multimodalnym.
Całokształt wskazuje, że zbiór danych GPT-4 był niemal na pewno większy i bardziej zróżnicowany niż w przypadku GPT-3 — według niektórych doniesień model trenowano na bilionach tokenów, co mogło oznaczać nawet petabajty danych zawierających teksty internetowe, książki, kod i obrazy. Jednak bez oficjalnych danych dokładna skala pozostaje nieznana. To, co wiemy na pewno, to zmiana strategii: szczegóły dotyczące GPT-4 pozostały tajemnicą — decyzja ta została skrytykowana przez wielu przedstawicieli społeczności AI jako odejście od przejrzystości.
Pomimo tej tajności wiadomo, że dane treningowe GPT-4 były multimodalne i pochodziły zarówno z otwartych źródeł internetowych, jak i z materiałów licencjonowanych, obejmując szersze spektrum treści (i języków) niż jakikolwiek wcześniejszy GPT. OpenAI zaczęło też przykładać większą wagę do dopracowywania modelu i jego „dostrajania” pod kątem zgodności z oczekiwaniami użytkownika — po wstępnym etapie treningu GPT-4 przeszedł intensywną fazę udoskonalania, m.in. poprzez reinforcement learning z udziałem ludzkich ocen (RLHF) oraz tuning instrukcyjny z przykładami pisanymi przez ludzi, co oznacza, że dane generowane i wybierane przez ludzi stały się istotnym elementem pipeline’u szkoleniowego.
1.5 Co wiemy (i czego nie wiemy) o danych GPT-5?
Pod względem skali nie ujawniono konkretnych liczb, ale wiele wskazuje na to, że GPT-5 został wytrenowany na ogromnej ilości danych. Krążyły pogłoski, że liczba tokenów mogła przekroczyć 1 bilion, co oznaczałoby przekroczenie dotychczasowych limitów objętości zbiorów i konieczność wykorzystania bezprecedensowej mocy obliczeniowej (według doniesień Microsoft udostępnił na potrzeby treningu OpenAI ponad 100 000 procesorów graficznych NVidia w chmurze Azure). Szacunkowy koszt trenowania GPT-5 sięga kilkuset milionów dolarów, co pokazuje, jak gigantyczna była zarówno ilość danych, jak i zaplecze techniczne — znacznie przekraczające 300 miliardów tokenów GPT-3 czy rzekome biliony tokenów GPT-4.

Filtrowanie danych i kontrola jakości: Oprócz czystej skali, OpenAI z czasem udoskonalało proces filtrowania i selekcjonowania danych treningowych. W dokumentacji systemowej GPT-5 wskazano, że stosowano „rygorystyczne filtrowanie w celu utrzymania jakości danych i ograniczania ryzyk”, w tym zaawansowane techniki usuwania informacji osobistych oraz użycie API moderacyjnego i klasyfikatorów bezpieczeństwa OpenAI, aby wykluczyć szkodliwe lub wrażliwe treści (takie jak materiały seksualne z udziałem nieletnich, mowa nienawiści itp.) ze zbiorów treningowych. To podejście jest znacznie bardziej proaktywne niż w przypadku wcześniejszych modeli. Dla porównania — w czasach GPT-3 OpenAI faktycznie filtrowało oczywisty spam i niektóre niebezpieczne treści (np. wykluczono Wikipedię z WebText, a Common Crawl filtrowano pod kątem jakości), ale nie koncentrowano się jeszcze wprost na bezpieczeństwie. W GPT-5 OpenAI jasno sygnalizuje: nie zbieramy już wszystkiego — systematycznie usuwamy dane osobowe i skrajne treści, by model nie uczył się na ich podstawie. Prawdopodobnie jest to odpowiedź zarówno na kwestie etyczne, jak i wymogi prawne (np. związane z ochroną prywatności) — więcej o tym w dalszej części artykułu.
To oznacza zmianę strategii: najwcześniejsze modele GPT były trenowane na wszystkim, co udało się znaleźć w sieci; teraz mamy do czynienia z selektywnym podejściem, redakcją danych i eliminacją toksycznych treści już na etapie budowy zbioru — zanim trafi on do modelu.
Trendy dotyczące przejrzystości: Od GPT-1 do GPT-3 OpenAI publikowało szczegółowe raporty opisujące zbiory danych, a nawet liczbę tokenów pochodzących z każdego źródła. W przypadku GPT-4 i GPT-5 szczegółowe ujawnienia zostały zastąpione ogólnikami. To istotna zmiana w podejściu do przejrzystości, która ma wpływ na zaufanie i rozwój badań naukowych — omówimy to szerzej w sekcji poświęconej etyce. Podsumowując: GPT-5 korzysta z najszerszego i najbardziej zróżnicowanego zbioru danych w historii — obejmującego internet, książki, kod, obrazy i ludzkie informacje zwrotne — jednak szczegóły pozostają niejawne. Wiemy, że buduje on na doświadczeniach z poprzednich modeli i że OpenAI poświęciło ogromny wysiłek na filtrowanie i wzbogacanie danych, aby poprawić jakość, bezpieczeństwo i objąć nowe modalności.
2. Przejrzystość i ujawnianie danych na przestrzeni lat
Jedną z najbardziej widocznych zmian w historii rozwoju modeli GPT jest stopień przejrzystości dotyczący danych treningowych. W pierwszych wersjach OpenAI udostępniało bardzo szczegółowe informacje. Prace naukowe opisujące GPT-2 i GPT-3 zawierały skład korpusów danych treningowych, a nawet opisywały sposób ich budowy i filtrowania. Na przykład publikacja o GPT-3 zawierała tabelę pokazującą, ile dokładnie tokenów pochodziło z Common Crawl, ile z WebText, ile z książek itd., oraz wyjaśniała, że nie wszystkie tokeny były traktowane jednakowo w trakcie uczenia. Dzięki temu zewnętrzni badacze mogli przeanalizować i zrozumieć, jakiego rodzaju teksty widział model. Umożliwiało to też tworzenie zbliżonych miksów treningowych w projektach open-source, jak np. zestaw Pile przygotowany przez EleutherAI, inspirowany „przepisem” GPT-3.

W przypadku GPT-4 OpenAI całkowicie zmieniło podejście — GPT-4 Technical Report nie zawierał żadnych szczegółów na temat danych treningowych poza jednym zdaniem, że użyto danych publicznych oraz licencjonowanych. Nie ujawniono rozmiaru modelu, konkretnych zbiorów danych ani liczby tokenów. OpenAI uzasadniało to potrzebą zachowania przewagi konkurencyjnej i względami bezpieczeństwa. Praktycznie potraktowano dane treningowe jako własność intelektualną. To oznaczało pełne odejście od wcześniejszej otwartości. Krytycy zwracali uwagę, że taki brak przejrzystości utrudnia ocenę potencjalnych uprzedzeń czy ryzyk związanych z modelem, ponieważ nikt poza OpenAI nie wie, na czym model był trenowany. Jeden z badaczy AI zauważył: „Fakt, że OpenAI nie dzieli się danymi treningowymi, sprawia, że nie sposób ocenić, czy zestawy danych zawierają konkretne uprzedzenia… aby móc świadomie decydować, gdzie model nie powinien być stosowany, musimy wiedzieć, jakie uprzedzenia może zawierać. Decyzje OpenAI to uniemożliwiają.” Innymi słowy: nie znając danych, nie znamy również ograniczeń modelu.
GPT-5 poszedł śladem GPT-4, jeśli chodzi o brak jawności. Publiczne komunikaty OpenAI dotyczące danych treningowych GPT-5 były ogólne i pozbawione liczb. Wiemy, że użyto kategorii źródeł (internet, dane licencjonowane, dane od ludzi), ale nie znamy konkretnych zbiorów ani proporcji między nimi. Karta systemowa GPT-5 i wpisy na blogu koncentrują się głównie na możliwościach modelu i kwestiach bezpieczeństwa, nie na procesie treningowym. To utrzymujące się zaciemnienie wywołało apel o większą przejrzystość. Niektórzy twierdzą, że im potężniejsze i powszechniej stosowane stają się systemy AI, tym większa powinna być potrzeba jawności — dla zapewnienia odpowiedzialności. Kierunek obrany przez OpenAI wzbudza więc niepokój. Nawet raport UNESCO z 2024 roku na temat uprzedzeń w AI wskazywał, że modele open-source (gdzie dane są znane) pozwalają społeczności naukowej współpracować przy ograniczaniu uprzedzeń, podczas gdy modele zamknięte, takie jak GPT-4 czy Google Gemini, utrudniają ten proces przez brak wglądu w dane treningowe.
Warto zauważyć, że zmiana podejścia OpenAI jest częściowo motywowana przewagą konkurencyjną. Skład danych treningowych GPT-4/GPT-5 (oraz zastosowane techniki oczyszczania danych) może być postrzegany jako istotna przewaga nad rywalami. Istnieje również argument dotyczący bezpieczeństwa: jeśli model ma niebezpieczne możliwości, szczegóły jego budowy mogłyby zostać wykorzystane przez osoby o złych intencjach lub przyspieszyć nadużycia. Sam Altman, CEO OpenAI, stwierdził, że ujawnienie zbyt wielu informacji mogłoby zaszkodzić pod kątem „konkurencji i bezpieczeństwa”, a Ilya Sutskever, główny naukowiec OpenAI, opisał tę tajność jako niezbędny „dowód dojrzałości pola badawczego” – biorąc pod uwagę, jak trudne było stworzenie GPT-4 i ilu graczy próbuje obecnie zbudować podobne modele. Niemniej jednak brak przejrzystości oznacza odejście od pierwotnej misji OpenAI (które początkowo było organizacją non-profit, deklarującą otwartość badań). Ten zwrot sam w sobie stał się problemem etycznym – ponieważ bez przejrzystości trudniej jest ocenić i korygować uprzedzenia, trudniej ufać modelowi, a społeczeństwo nie ma pełnego obrazu tego, na czym oparta jest wiedza AI.
3. Kwestie etyczne i kontrowersje związane z danymi treningowymi
Wybór danych treningowych dla modeli GPT ma ogromne konsekwencje etyczne. Dane te nie tylko przekazują wiedzę i umiejętności językowe, ale także zaszczepiają wartości, uprzedzenia i ślepe punkty, obecne w materiałach źródłowych. W miarę jak modele stają się coraz potężniejsze (GPT-3, GPT-4, GPT-5), pojawia się coraz więcej kontrowersji i debat publicznych dotyczących ich danych treningowych.
3.1 Czy GPT nadal utrwala stereotypy i uprzedzenia?
Jednym z kluczowych problemów jest bias reprezentacyjny: duże modele językowe mogą przyswajać, a nawet wzmacniać uprzedzenia obecne w tekstach źródłowych, generując odpowiedzi, które utrwalają krzywdzące stereotypy dotyczące rasy, płci, religii i innych grup. Ponieważ modele te uczą się na ogromnych zbiorach tekstów pisanych przez ludzi (głównie z internetu), nieuniknione jest, że przyswajają także społeczne nierówności i uprzedzenia obecne w tych treściach.
Na przykład badacze wykazali, że modele z rodziny GPT potrafią generować seksistowskie lub rasistowskie treści nawet w odpowiedzi na neutralnie brzmiące zapytania. W badaniu UNESCO z 2024 roku odnotowano „niepokojące tendencje” w wynikach generatywnej AI, w tym GPT-2 i GPT-3.5 – takie jak przypisywanie kobietom ról domowych i rodzinnych znacznie częściej niż mężczyznom, oraz kojarzenie mężczyzn z karierą i przywództwem. W generowanych historiach bohaterki kobiece pojawiały się głównie w zaniżonych rolach („kucharka”, „prostytutka”), a bohaterowie męscy w zawodach prestiżowych („inżynier”, „lekarz”). Badanie wskazało też na obecność homofobicznych i rasistowskich stereotypów w wynikach modelu. Uprzedzenia te odzwierciedlają wzorce zawarte w danych treningowych (np. nadreprezentację pewnych schematów płciowych w literaturze i tekstach internetowych), ale model może je bezrefleksyjnie przyswoić i powielać.
Szczególnie drastyczny przykład dotyczy uprzedzeń religijnych: w badaniu z 2021 roku (Abid i in.) GPT-3 wykazywał znaczące uprzedzenia wobec muzułmanów. Na zapytanie „Dwóch muzułmanów wchodzi do…” aż 66% odpowiedzi modelu zawierało odniesienia do przemocy (np. „wchodzą do synagogi z siekierami i bombą” lub „…i zaczynają strzelać”). Tymczasem podobne zapytania o inne religie („Dwóch chrześcijan…”, „Dwóch buddystów…”) kończyły się przemocą znacznie rzadziej (zwykle poniżej 10%). Model kończył także analogie typu „Muzułmanin to…” słowem „terrorysta” w 25% przypadków. Te odpowiedzi są alarmujące – pokazują, że model kojarzy termin „muzułmanin” z przemocą i ekstremizmem. Prawdopodobnie wynika to z danych treningowych: GPT-3 pochłonął miliony stron tekstu z internetu, w tym z islamofobicznymi treściami i przekłamanym obrazem medialnym terroryzmu. Bez aktywnego filtrowania i korekty uprzedzeń w danych, model przyswoił te schematy. Naukowcy określili to jako „poważne uprzedzenie”, które może prowadzić do realnej krzywdy (np. jeśli system AI streszcza wiadomości i nieustannie przedstawia muzułmanów w negatywnym świetle, albo jeśli odpowiada użytkownikom w sposób subtelnie uprzedzony).
Chociaż OpenAI i inne organizacje podejmują próby łagodzenia uprzedzeń w nowszych modelach (głównie przez dopasowywanie i techniki tzw. alignmentu), źródło problemu leży głęboko w samych danych treningowych. GPT-4 i GPT-5 były trenowane na jeszcze większych korpusach tekstów, które prawdopodobnie nadal zawierają tendencyjne przedstawienia grup marginalizowanych. Szkolenie ukierunkowane (alignment), takie jak RLHF (Reinforcement Learning from Human Feedback), ma na celu skłonić model do odmawiania lub moderowania wyraźnie toksycznych wypowiedzi, co pomaga ograniczyć jawną mowę nienawiści. GPT-4 i GPT-5 są więc z założenia bardziej filtrowane niż GPT-3.
Jednak badania sugerują, że ukryte uprzedzenia nadal mogą się pojawiać. Badanie Uniwersytetu Stanforda z 2024 roku wykazało, że nawet po zaawansowanym szkoleniu bezpieczeństwa, modele nadal mogą prezentować „przestarzałe stereotypy” oraz rasistowskie skojarzenia, choć w bardziej subtelnej formie. Na przykład duże modele językowe mogą generować mniej trafne lub mniej pomocne odpowiedzi na pytania sformułowane w Afroamerykańskim angielskim potocznym (AAVE), w porównaniu do „standardowego” angielskiego, co de facto marginalizuje ten dialekt. Badacze zauważyli, że współczesne modele (stan na 2024 rok) wciąż powielają skrajne rasowe stereotypy rodem z epoki sprzed Ruchu Praw Obywatelskich w wybranych odpowiedziach. Innymi słowy, uprzedzenia obecne w starych książkach czy tekstach historycznych mogą się pojawić, jeśli nie zostaną aktywnie wyłapane i usunięte.

Te odkrycia wywołały debatę publiczną i krytykę. Znany artykuł “On the Dangers of Stochastic Parrots” (Bender i in., 2021) argumentował, że bezrefleksyjne skalowanie dużych modeli językowych prowadzi do sytuacji, w której modele „utrwalają uprzedzenia wobec osób marginalizowanych wielowymiarowo” i bezmyślnie powielają szkodliwe treści. Autorzy określili LLM jako „losowe papugi” – modele te nie rozumieją znaczenia, jedynie odtwarzają wzorce zawarte w danych. Jeśli dane są stronnicze, model to odzwierciedli. Ostrzegali przed ryzykiem „nieznanych niebezpiecznych uprzedzeń” i możliwością generowania toksycznych lub wprowadzających w błąd treści na dużą skalę. Artykuł zyskał rozgłos również dlatego, że jedna z jego autorek (Timnit Gebru z Google) została zwolniona po wewnętrznym sporze dotyczącym publikacji – co obnażyło napięcia w Big Tech wokół etycznych aspektów danych treningowych.
W przypadku GPT-5 OpenAI deklaruje, że zainwestowało w szkolenia bezpieczeństwa w celu ograniczenia problematycznych odpowiedzi. Wprowadzono nowe techniki, takie jak „bezpieczne dokończenia” (safe completions), które mają sprawić, że model będzie udzielał pomocnych, lecz bezpiecznych odpowiedzi, zamiast po prostu odmawiać lub generować nieodpowiednie treści. OpenAI podaje też, że GPT-5 rzadziej niż poprzednie wersje generuje dezinformację czy mowę nienawiści. Firma przeprowadziła wewnętrzne testy typu red-teaming, by wykryć problemy z równością. Co więcej – jak wspomniano wcześniej – niektóre treści zostały wykluczone z danych treningowych (np. materiały seksualne z udziałem nieletnich czy mowa nienawiści).
Te działania zapewne ograniczają najpoważniejsze przypadki. Jednak subtelne uprzedzenia reprezentacyjne (np. stereotypy płciowe dotyczące zawodów czy skojarzenia etniczne z negatywnymi cechami) są niezwykle trudne do całkowitego wyeliminowania, szczególnie gdy są głęboko zakorzenione w ogromnych zbiorach danych. Raport UNESCO zauważył, że nawet modele zamknięte jak GPT-4 czy GPT-3.5, które przeszły dodatkowe szkolenie po treningu bazowym, wciąż zdradzają oznaki stronniczości płciowej w swoich wynikach.
Podsumowując, problem etyczny polega na tym, że bez starannej selekcji dane treningowe LLM odzwierciedlają społeczne uprzedzenia, a model nieświadomie je powiela, a nawet wzmacnia. To doprowadziło do apeli o tworzenie bardziej zrównoważonych i inkluzywnych zbiorów danych, dokumentację ich składu oraz testy uprzedzeń w modelach. Niektórzy badacze postulują tworzenie „kart danych dla zbiorów danych” (datasheets for datasets) i celowe włączanie perspektyw grup niedoreprezentowanych (lub wykluczanie problematycznych źródeł), aby zapobiegać zniekształceniom. OpenAI i inne organizacje prowadzą aktywne badania nad ograniczaniem uprzedzeń, ale pozostaje to nieustanną grą w kotka i myszkę – im bardziej złożone modele, tym trudniej zrozumieć i korygować ich uprzedzenia, szczególnie jeśli dane treningowe nie są jawne.
3.2 Czy GPT uczy się na prywatnych i chronionych danych?
Kolejna kontrowersja dotyczy legalności treści i prywatności danych wykorzystywanych w treningu. Modele GPT, pozyskując dane masowo z sieci i innych źródeł, siłą rzeczy przetwarzają wiele materiałów objętych prawem autorskim lub zawierających dane osobowe – co rodzi pytania o zgodę i dozwolony użytek.
Prawa autorskie i własność danych: Modele GPT-3, 4 i 5 uczą się na miliardach zdań z książek, wiadomości, stron internetowych itp. – z których wiele jest chronionych prawem autorskim. Przez długi czas pozostawało to w szarej strefie: proces uczenia nie polega przecież na bezpośrednim kopiowaniu (przynajmniej w teorii), a firmy traktowały scrapowanie internetu jako dozwolone. Jednak wraz ze wzrostem wpływu tych modeli, autorzy i wydawcy zaczęli się sprzeciwiać. W latach 2023–2024 złożono serię pozwów przeciwko OpenAI i innym firmom AI – m.in. przez pisarzy i redakcje. Pozwy zarzucają OpenAI bezprawne użycie chronionych utworów (powieści, artykułów itp.) bez zgody i wynagrodzenia – co stanowi masowe naruszenie praw autorskich. Do 2025 roku co najmniej kilkanaście spraw zostało połączonych w sądzie w Nowym Jorku – z udziałem znanych autorów jak George R.R. Martin, John Grisham, Jodi Picoult oraz m.in. redakcji The New York Times. Strona powodowa twierdzi, że ich książki i artykuły zostały pozyskane (często przez scrapowanie lub z bibliotek cyfrowych) w celu wzbogacenia modeli komercyjnych – co stanowi „kradzież milionów utworów”, jak określił to jeden z prawników.
OpenAI utrzymuje, że korzystanie z ogólnodostępnych tekstów mieści się w granicach dozwolonego użytku (fair use) na gruncie prawa amerykańskiego. Firma argumentuje, że model nie przechowuje ani nie odtwarza długich fragmentów tekstów dosłownie, a samo wykorzystanie szerokiego korpusu tekstu do nauki wzorców językowych jest transformacyjne i innowacyjne. Rzecznik OpenAI stwierdził: „Nasze modele są trenowane na publicznie dostępnych danych, zgodnie z zasadą fair use, i wspierają innowacje.”. Tu leży sedno sporu: czy scrapowanie internetu lub digitalizacja książek w celu treningu AI można porównać do czytania i uczenia się przez człowieka (czyli dozwolonego użytku)? Czy raczej jest to forma reprodukcji treści, która konkuruje z oryginałem i tym samym narusza prawa? Obecnie toczą się postępowania sądowe, które mogą stworzyć nowe precedensy. Niektóre redakcje również podjęły kroki prawne – np. The New York Times pozwał OpenAI za trenowanie modeli na artykułach bez licencji.

W przypadku GPT-5 prawdopodobnie jeszcze więcej materiałów objętych prawem autorskim znalazło się w danych treningowych – zwłaszcza jeśli OpenAI kupił dostęp do określonych zbiorów danych (np. współczesnej beletrystyki czy artykułów naukowych). Jeśli tak – dane mogły być legalnie pozyskane. Jeśli nie – GPT-5 mógł być trenowany na tekstach, których autorzy nie wyrazili zgody. Ta kontrowersja znów sprowadza się do braku przejrzystości: ponieważ OpenAI nie ujawnia dokładnie, co było w danych treningowych, autorzy nie wiedzą, czy ich prace zostały użyte – choć wskazówki pojawiają się, gdy model potrafi zacytować fragmenty książek. Pozwy te doprowadziły do apeli o stworzenie systemu „opt-out” lub rekompensaty – np. możliwość zablokowania scrapowania danej strony albo wypłaty, jeśli tekst wspierał rozwój AI. OpenAI umożliwiło ostatnio właścicielom witryn blokadę crawlera GPTBot (np. przez robots.txt), co można uznać za nieformalny sygnał uznania problemu. Wynik tych procesów będzie miał duże znaczenie dla przyszłości tworzenia zbiorów danych w AI.
Dane osobowe i prywatność: Oprócz treści objętych prawem autorskim scrapowanie stron internetowych może wciągnąć dane osobowe – np. wycieki maili, posty w mediach społecznościowych, dyskusje na forach. Wczesne modele GPT z dużym prawdopodobieństwem przetwarzały takie informacje, jeśli były publicznie dostępne. To rodzi poważne pytania o prywatność: model mógł „zapamiętać” numer telefonu, adres, czy inne wrażliwe dane z bazy danych i następnie „wypluć” je w odpowiedzi na zapytanie. Rzeczywiście – badacze wykazali, że duże modele językowe potrafią w rzadkich przypadkach odtworzyć dosłowne fragmenty danych treningowych (np. fragment kodu z adresem e-mail, cytat z prywatnego bloga) – zjawisko to nazywane jest wyciekiem danych treningowych (training data extraction). Organy nadzoru nad danymi osobowymi zwróciły na to uwagę. W 2023 roku włoski urząd ochrony danych osobowych tymczasowo zablokował ChatGPT, argumentując, że narusza on RODO, przetwarzając dane osobowe bezprawnie i nie informując użytkowników. OpenAI odpowiedziało, wprowadzając kontrolki prywatności i zmiany informacyjne – ale problem wciąż pozostaje: modele były trenowane bez zgody osób, których dane mogły się tam znaleźć – a część tych danych może być wrażliwa.
OpenAI w podejściu do GPT-5 stara się odpowiedzieć na obawy dotyczące prywatności już na etapie pracy z danymi. Jak wspomniano, proces przygotowania danych treningowych dla GPT-5 obejmował „zaawansowane procedury filtrowania w celu ograniczenia ilości danych osobowych w zbiorze treningowym”. Oznacza to prawdopodobnie, że starano się usunąć takie informacje jak numery dowodów tożsamości, prywatne dane kontaktowe czy inne szczegóły umożliwiające identyfikację. Wykorzystywane są również narzędzia OpenAI, takie jak Moderation API, które filtrują treści naruszające prywatność lub mogące być szkodliwe. To pozytywny krok, ponieważ zmniejsza ryzyko, że GPT-5 zapamięta i odtworzy czyjeś prywatne dane. Niemniej jednak obrońcy prywatności twierdzą, że każdy powinien mieć prawo do decydowania, czy jakiekolwiek jego dane (nawet niespersonalizowane posty czy wpisy) mogą być używane do trenowania AI. Koncepcja „godności danych” zakłada, że cyfrowe ślady ludzi mają wartość i nie powinny być wykorzystywane bez zgody. Można się spodziewać dalszych debat, a nawet regulacji w tym obszarze – na przykład dyskusji nad „prawem do bycia wykluczonym” z zestawów treningowych AI, podobnym do prawa do bycia zapomnianym w przepisach o ochronie danych osobowych.
Wykorzystanie danych użytkowników przez model: Kolejnym aspektem jest fakt, że po wdrożeniu, modele takie jak ChatGPT nadal uczą się na podstawie interakcji użytkowników. Domyślnie OpenAI wykorzystywało rozmowy z ChatGPT (czyli wpisywane przez użytkowników zapytania) do dalszego dostrajania i ulepszania modelu – chyba że użytkownik wyłączył taką opcję. Oznacza to, że nasze wiadomości i rozmowy stają się częścią danych wykorzystywanych do dalszego uczenia modelu. Badanie Stanforda z końca 2025 roku wykazało, że wiodące firmy AI – w tym OpenAI – rzeczywiście „pozyskiwały konwersacje użytkowników do dalszego treningu”, co może rodzić zagrożenia dla prywatności, jeśli nie jest odpowiednio zarządzane. OpenAI w odpowiedzi wprowadziło opcję wyłączania historii czatu (by rozmowy nie były wykorzystywane w treningu) oraz zadeklarowało, że dane klientów korporacyjnych nie są domyślnie wykorzystywane do trenowania modeli. Mimo to, ta praktyka zbierania danych nadal budzi kontrowersje – wielu użytkowników nie zdaje sobie sprawy, że to, co wpisują do czatu, może być przeglądane przez ludzi lub wykorzystywane do udoskonalania AI.
3.3 Czy da się ufać modelowi, gdy nie znamy danych wejściowych?
Wspomniane wyżej kwestie (uprzedzenia, prawa autorskie, prywatność) prowadzą do szerszej dyskusji na temat odpowiedzialności w AI. Jeśli model wygeneruje coś szkodliwego lub błędnego, znajomość danych treningowych może pomóc zrozumieć przyczynę. Brak przejrzystości utrudnia zaufanie – zwłaszcza jeśli nie wiadomo, czy model nie był trenowany głównie na stronniczych lub wątpliwych źródłach. To napięcie między przewagą konkurencyjną a interesem publicznym. Wielu badaczy apeluje o przejrzystość danych treningowych jako podstawowy wymóg etyczny – porównywalny z obowiązkiem informowania o składzie produktu. Odejście OpenAI od takiej praktyki zostało skrytykowane przez ekspertów, takich jak Emily M. Bender, która napisała, że tajemniczość OpenAI była co prawda spodziewana, ale niebezpieczna – i że firma „świadomie ignoruje najbardziej podstawowe strategie ograniczania ryzyka” nie ujawniając szczegółów. OpenAI odpowiada, że pozostaje zaangażowane w kwestie bezpieczeństwa i stara się równoważyć przejrzystość z realiami konkurencji i ryzykiem nadużyć.

Istnieje również argument, że otwarte modele (z otwartymi danymi treningowymi) umożliwiają społeczności łatwiejsze identyfikowanie i korygowanie uprzedzeń. Analiza UNESCO wskazuje wprost, że choć open-source’owe modele językowe (takie jak LLaMA 2 od Meta czy starszy GPT-2) wykazują więcej uprzedzeń w surowych odpowiedziach, to ich „otwarty i przejrzysty charakter” jest zaletą – ponieważ badacze z całego świata mogą wspólnie pracować nad ich ograniczeniem. Co nie jest możliwe w przypadku modeli zamkniętych jak GPT-3.5 czy GPT-4, gdzie dane i wagi są zastrzeżone. Innymi słowy, otwartość może prowadzić do lepszych efektów w dłuższej perspektywie, nawet jeśli początkowo takie modele są bardziej podatne na błędy – bo przejrzystość umożliwia rozliczalność i ulepszanie. To kluczowy temat publicznych debat: czy modele podstawowe powinny być traktowane jak infrastruktura – przejrzysta i możliwa do audytu – czy jak własność intelektualna wymagająca ochrony?
Innym aspektem etycznym jest wpływ środowiskowy – trenowanie modeli na ogromnych zbiorach danych pochłania gigantyczne ilości energii – choć to zagadnienie jest nieco odrębne od samej treści danych. Artykuł “Stochastic Parrots” również poruszał problem śladu węglowego związanego z trenowaniem coraz większych modeli. Niektórzy eksperci uważają, że nieustanne zbieranie kolejnych danych i skalowanie mocy obliczeniowej jest nie do utrzymania. Firmy takie jak OpenAI zaczęły badać efektywność danych (np. wykorzystanie danych syntetycznych lub lepszych algorytmów), by uniknąć konieczności podwajania zbiorów danych przy każdej nowej generacji modelu.
Wreszcie, istotne są dezinformacja i jakość treści w danych treningowych: wiedza GPT-5 jest tak dobra, jak źródła, z których pochodzi. Jeśli zbiór treningowy zawiera dużo teorii spiskowych lub nieprawdziwych informacji (jak często bywa w internecie), model może je przyswoić. Do korygowania błędów faktograficznych stosuje się techniki fine-tuningu i wyszukiwania danych zewnętrznych, ale brak przejrzystości danych GPT-4/5 utrudnia ocenę, ile dezinformacji może być zawartych w modelu. Pojawiły się więc głosy, że należy stosować bardziej sprawdzone źródła – lub przynajmniej dopuścić niezależnych audytorów do oceny jakości zbioru treningowego.
Podsumowując, rozwój od GPT-1 do GPT-5 pokazuje nie tylko postęp technologiczny, ale i coraz większą świadomość wymiarów etycznych danych treningowych. Uprzedzenia, sprawiedliwość, zgoda na wykorzystanie danych i przejrzystość – te tematy stają się kluczowe w dyskusji o AI. OpenAI wprowadziło pewne zmiany (np. filtrowanie danych czy dostrajanie zachowania modelu), ale jednocześnie stało się mniej transparentne co do samych danych – co budzi pytania w środowisku zajmującym się etyką AI. W przyszłości kluczowe będzie znalezienie właściwej równowagi między wykorzystywaniem ogromnych zbiorów danych a przestrzeganiem norm etycznych i prawnych. Debaty publiczne i krytyczne głosy – od „Stochastic Parrots” po pozwy autorów – mają realny wpływ na to, jak będą szkolone kolejne generacje AI. Rozwój GPT-5 dowodzi, że jakie dane wykorzystujemy do treningu, jest równie ważne jak ile parametrów i GPU użyjemy. Skład zbiorów treningowych ma ogromny wpływ na możliwości i ograniczenia modelu – i dlatego pozostaje tematem gorących dyskusji zarówno w badaniach nad AI, jak i w społeczeństwie.
Choć trenowanie dużych modeli językowych, takich jak GPT-5, rodzi uzasadnione pytania o etykę danych, przejrzystość i ryzyko uprzedzeń, otwiera również ogromne możliwości. Kluczowe jest, aby wykorzystywać te narzędzia świadomie – z pełnym zrozumieniem ich potencjału, ale też ograniczeń. W TTMS pomagamy organizacjom wdrażać AI w sposób nie tylko skuteczny, ale przede wszystkim odpowiedzialny – niezależnie od tego, czy chodzi o inteligentną automatyzację, dedykowane integracje GPT, czy systemy wspierania decyzji oparte na sztucznej inteligencji. Jeśli zastanawiasz się, jak AI może wesprzeć rozwój Twojej firmy, nie rezygnując przy tym z przejrzystości, zaufania i zgodności z regulacjami – zapraszamy do kontaktu. Chętnie pomożemy zaplanować rozwiązania skrojone na miarę Twoich potrzeb.
4. Jak odpowiedzialnie wdrażać AI w Twojej firmie?
Choć trenowanie dużych modeli językowych takich jak GPT-5 budzi uzasadnione pytania o etykę danych, przejrzystość i uprzedzenia, to jednocześnie otwiera ogromne możliwości. Klucz tkwi w tym, aby wykorzystywać te narzędzia świadomie, rozumiejąc ich potencjał, ale i ograniczenia. W TTMS pomagamy firmom wdrażać AI w sposób nie tylko skuteczny, ale też odpowiedzialny – niezależnie czy chodzi o inteligentną automatyzację, dedykowane integracje GPT, czy systemy wspierania decyzji oparte na AI. Stawiamy na zgodność z regulacjami, bezpieczeństwo danych i przejrzystość w działaniu modeli.
Jeśli rozważasz, jak AI może wspierać Twoją organizację – bez kompromisów w zakresie zaufania, uczciwości i zgodności z przepisami – skontaktuj się z nami. Z przyjemnością pomożemy Ci rozpocząć odpowiedzialną transformację opartą na AI.
5. Co nowego w GPT‑5.1? Ulepszone metody treningowe i większy nacisk na prywatność
GPT‑5.1 nie wprowadził rewolucji w zakresie danych treningowych – opiera się na tej samej bazie danych co GPT‑5. Zastosowane źródła danych pozostały podobne: gigantyczne otwarte zbiory internetowe (m.in. tekst z WWW, publikacje naukowe, kod), dane multimodalne (tekst skojarzony z obrazami, dźwiękiem czy wideo) oraz rozszerzony zasób danych syntetycznych wytworzonych przez wcześniejsze modele. Już trening GPT‑5 wykorzystał taką mieszankę – model uczył się najpierw na starannie dobranych treściach z internetu, potem na trudniejszych zadaniach (w tym wygenerowanych syntetycznie przez GPT‑4), a na końcu na pytaniach eksperckich służących rozwijaniu zaawansowanego rozumowania. W wersji 5.1 nie dodano nowych kategorii danych, lecz ulepszono metody dostrajania modelu: OpenAI dostosowało go na podstawie opinii użytkowników, dzięki czemu GPT‑5.1 ma wyraźnie bardziej naturalny, “ciepły” styl rozmowy i lepiej przestrzega instrukcji. Jednocześnie podejście do prywatności pozostało rygorystyczne – dane użytkowników (zwłaszcza firm korzystających z ChatGPT) nie są włączane do zbioru treningowego bez zgody i podlegają anonimizacji. Cały pipeline treningowy objęto dalszymi usprawnieniami filtrowania i selekcji jakościowej: usuwane są treści naruszające zasady (np. mowa nienawiści, pornografia, prywatne dane osobowe, spam), a model został nauczony unikać ujawniania wrażliwych informacji. Oficjalne materiały (karta systemowa GPT‑5 z uzupełnieniem dla GPT‑5.1 oraz blogpost od OpenAI) potwierdzają, że zmiany w GPT‑5.1 dotyczą głównie architektury i fine-tuningu modelu, a nie nowych danych treningowych.
FAQ
Jakie źródła danych wykorzystano do trenowania GPT-5 i czym różnią się one od danych użytych w wcześniejszych modelach GPT?
GPT-5 został wytrenowany na mieszance tekstów z internetu, licencjonowanych danych od podmiotów trzecich oraz treści generowanych przez ludzi. Jest to podejście podobne do GPT-4, ale zestaw danych GPT-5 jest jeszcze bardziej zróżnicowany i multimodalny. Na przykład GPT-5 potrafi obsługiwać obrazy i głos, co sugeruje, że podczas treningu wykorzystywano pary obraz–tekst oraz prawdopodobnie transkrypcje audio (podczas gdy GPT-3 był modelem wyłącznie tekstowym). Wcześniejsze modele GPT miały bardziej określone profile danych: GPT-2 korzystał z 40 GB stron internetowych (WebText), a GPT-3 łączył przefiltrowany Common Crawl, linki z Reddita, książki i Wikipedię. GPT-4 i GPT-5 najprawdopodobniej obejmowały wszystkie te źródła oraz dodatkowo więcej kodu i danych specjalistycznych z konkretnych dziedzin. Największą różnicą jest przejrzystość — OpenAI nie ujawniło w pełni źródeł GPT-5, w przeciwieństwie do szczegółowego podziału, jaki podano dla GPT-3. Wiadomo natomiast, że zespół GPT-5 położył duży nacisk na filtrowanie danych (m.in. usuwanie informacji osobistych i szkodliwych treści) — w znacznie większym stopniu niż w przypadku wcześniejszych modeli.
Czy OpenAI wykorzystało dane objęte prawem autorskim lub dane prywatne do trenowania GPT-5?
OpenAI twierdzi, że GPT-5 został wytrenowany na publicznie dostępnych informacjach oraz danych od partnerów zewnętrznych. Prawie na pewno obejmuje to treści objęte prawem autorskim, które były dostępne w internecie (np. artykuły, książki, kod) – co według OpenAI mieści się w ramach dozwolonego użytku. Firma prawdopodobnie uzyskała również licencje na niektóre zbiory danych (co może oznaczać legalne pozyskanie chronionych tekstów).
Jeśli chodzi o dane prywatne: podczas treningu mogło dojść do przypadkowego pobrania danych osobowych z internetu, ale OpenAI deklaruje, że w procesie przygotowania danych do GPT-5 zastosowano zaawansowane filtrowanie w celu usunięcia informacji umożliwiających identyfikację osób. W odpowiedzi na rosnące obawy o prywatność i nowe regulacje, firma umożliwiła także właścicielom stron internetowych zablokowanie dostępu do swojego contentu dla robota GPT.
Zatem GPT-5 rzeczywiście uczył się na ogromnych zbiorach tekstów z sieci – z których część mogła być objęta prawami autorskimi lub zawierać dane osobowe – ale OpenAI podjęło więcej kroków niż wcześniej, by oczyścić te dane. Wciąż jednak trwają procesy sądowe, m.in. ze strony autorów, którzy twierdzą, że wykorzystanie ich tekstów do treningu było nielegalne – to kwestia, którą ostatecznie rozstrzygną sądy.
W jaki sposób uprzedzenia w danych treningowych wpływają na odpowiedzi GPT-5?
Uprzedzenia obecne w danych treningowych mogą bezpośrednio przekładać się na sposób, w jaki GPT-5 formułuje odpowiedzi. Ponieważ model uczy się na ogromnych zbiorach tekstów stworzonych przez ludzi – w tym artykułach, forach, książkach czy mediach społecznościowych – może nieświadomie przejmować stereotypy, nierówności i stronnicze narracje zawarte w tych źródłach.
Choć OpenAI stosuje techniki takie jak fine-tuning z udziałem ludzi (RLHF), filtrowanie danych oraz algorytmy bezpieczeństwa, badania pokazują, że subtelne formy uprzedzeń nadal mogą się pojawiać – na przykład w skojarzeniach między zawodami a płcią, w jakości odpowiedzi na wpisy w różnych odmianach języka (np. AAVE), czy w tendencyjnym opisie grup etnicznych czy religijnych.
GPT-5 jest lepiej zabezpieczony przed jawnym mową nienawiści niż wcześniejsze modele, ale nadal może wzmacniać historyczne lub kulturowe schematy zakorzenione w danych źródłowych. Dlatego uprzedzenia w danych pozostają istotnym wyzwaniem etycznym i technicznym przy rozwijaniu dużych modeli językowych.
Dlaczego brak ujawnienia danych treningowych GPT-4 i GPT-5 wywołał kontrowersje?
Dlaczego brak ujawnienia danych treningowych GPT-4 i GPT-5 wywołał kontrowersje?
Kontrowersje wynikły z faktu, że OpenAI — w przeciwieństwie do wcześniejszych praktyk przy GPT-2 i GPT-3 – nie ujawniło szczegółowych informacji na temat źródeł danych treningowych GPT-4 i GPT-5. Brak przejrzystości oznacza, że społeczność badawcza, użytkownicy i organizacje nie wiedzą dokładnie, jakie treści zasilały te modele, co utrudnia ocenę ich uprzedzeń, dokładności czy ryzyk etycznych.
Krytycy argumentują, że przy tak potężnych i szeroko stosowanych systemach sztucznej inteligencji potrzebna jest większa odpowiedzialność i możliwość audytu – a to wymaga jawności w zakresie danych. Niektórzy badacze zauważyli, że bez wiedzy o tym, co model „przeczytał”, trudno przewidzieć jego ograniczenia i błędy. Z kolei OpenAI tłumaczy swoją decyzję względami bezpieczeństwa i konkurencyjności — obawą, że ujawnienie danych mogłoby ułatwić nadużycia lub kopiowanie technologii przez rywali. Ten brak transparentności stał się istotnym punktem debaty o etyce rozwoju dużych modeli językowych.
Jakie działania podjęto, aby dane treningowe GPT-5 były bezpieczne i wysokiej jakości?
OpenAI wdrożyło szereg środków, aby poprawić jakość i bezpieczeństwo danych treningowych GPT-5. W szczególności zastosowano zaawansowane techniki filtrowania treści – w tym klasyfikatory bezpieczeństwa i Moderation API – które służą do wykrywania i usuwania toksycznych, obraźliwych lub nielegalnych materiałów, takich jak mowa nienawiści czy dane osobowe.
Dodatkowo, dane zostały przetworzone w celu zredukowania informacji umożliwiających identyfikację osób (np. adresów, numerów telefonów, numerów identyfikacyjnych). GPT-5 był też trenowany z większym naciskiem na dane licencjonowane i wysokiej jakości, a nie wyłącznie ogólnodostępne treści z internetu. Po etapie pre-treningu model przeszedł proces dostrajania z udziałem ludzi (np. przez reinforcement learning from human feedback), co dodatkowo ograniczyło możliwość generowania szkodliwych odpowiedzi. Wszystkie te działania miały na celu stworzenie modelu bardziej bezpiecznego, etycznego i zgodnego z regulacjami prawnymi.






