Did you know that GPT-5 may have been trained on transcripts of your favorite YouTube videos, Reddit threads you once upvoted, and even code you casually published on GitHub? As language models become more powerful, their hunger for vast and diverse datasets grows—and so do the ethical questions. What exactly went into GPT-5’s mind? And how does that compare to what fueled its predecessors like GPT-3 or GPT-4? This article breaks down the known (and unknown) facts about GPT-5’s training data and explores the evolving controversy over transparency, consent, and fairness in AI training.
1. Training Data Evolution from GPT-1 to GPT-5
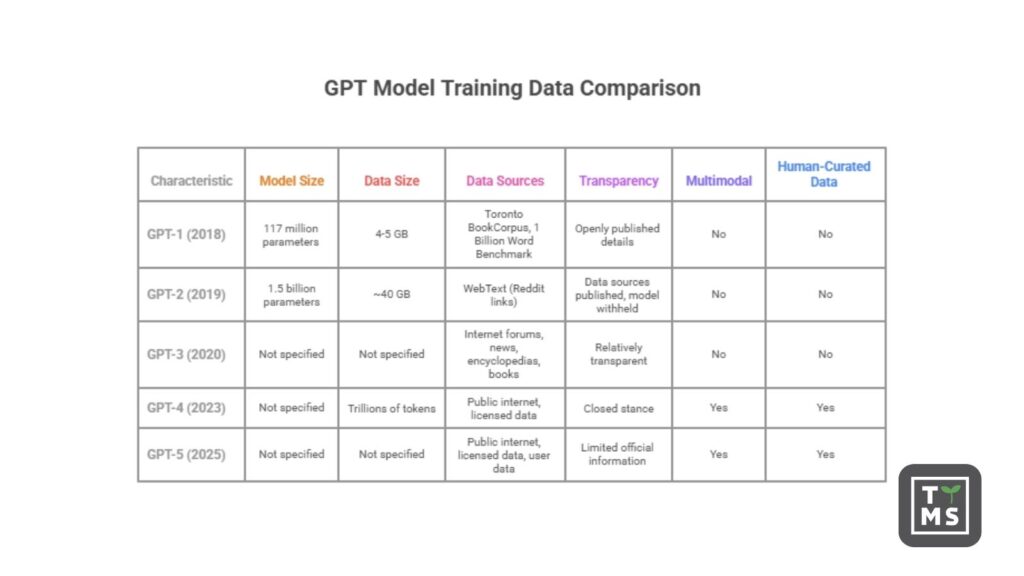
GPT-1 (2018): The original Generative Pre-Trained Transformer (GPT-1) was relatively small by today’s standards (117 million parameters) and was trained on a mix of book text and online text. Specifically, OpenAI’s 2018 paper describes GPT-1’s unsupervised pre-training on two corpora: the Toronto BookCorpus (~800 million words of fiction books) and the 1 Billion Word Benchmark (a dataset of ~1 billion words, drawn from news articles). This gave GPT-1 a broad base in written English, especially long-form narrative text. The use of published books introduced a variety of literary styles, though the dataset has been noted to include many romance novels and may reflect the biases of that genre. GPT-1’s training data was a relatively modest 4-5 GB of text, and OpenAI openly published these details in its research paper, setting an early tone of transparency.
GPT-2 (2019): With 1.5 billion parameters, GPT-2 dramatically scaled up both model size and data. OpenAI created a custom dataset called WebText by scraping content from the internet: specifically, they collected about 8 million high-quality webpages sourced from Reddit links with at least 3 upvotes. This amounted to ~40 GB of text drawn from a wide range of websites (excluding Wikipedia) and represented a 10× increase in data over GPT-1. The WebText strategy assumed that Reddit’s upvote filtering would surface pages other users found interesting or useful, yielding naturally occurring demonstrations of many tasks in the data. GPT-2 was trained to simply predict the next word on this internet text, which included news articles, blogs, fiction, and more. Notably, OpenAI initially withheld the full GPT-2 model in February 2019, citing concerns it could be misused for generating fake news or spam due to the model’s surprising quality. (They staged a gradual release of GPT-2 models over time.) However, the description of the training data itself was published: “40 GB of Internet text” from 8 million pages. This openness about data sources (even as the model weights were temporarily withheld) showed a willingness to discuss what the model was trained on, even as debates began about the ethics of releasing powerful models.
GPT-3 (2020): GPT-3’s release marked a new leap in scale: 175 billion parameters and hundreds of billions of tokens of training data. OpenAI’s paper “Language Models are Few-Shot Learners” detailed an extensive dataset blend. GPT-3 was trained on a massive corpus (~570 GB of filtered text, totaling roughly 500 billion tokens) drawn from five main components:
- Common Crawl (Filtered): A huge collection of web pages scraped from 2016-2019, after heavy filtering for quality, which provided ~410 billion tokens (around 60% of GPT-3’s training mix). OpenAI filtered Common Crawl using a classifier to retain pages similar to high-quality reference corpora, and performed fuzzy deduplication to remove redundancies. The result was a “cleaned” web dataset spanning millions of sites (predominantly English, with an overrepresentation of US-hosted content). This gave GPT-3 a very broad knowledge of internet text, while filtering aimed to skip low-quality or nonsensical pages.
- WebText2: An extension of the GPT-2 WebText concept – OpenAI scraped Reddit links over a longer period than the original WebText, yielding about 19 billion tokens (22% of training). This was essentially “curated web content” selected by Reddit users, presumably covering topics that sparked interest online, and was given a higher sampling weight during training because of its higher quality.
- Books1 & Books2: Two large book corpora (referred to only vaguely in the paper) totaling 67 billion tokens combined. Books1 was ~12B tokens and Books2 ~55B tokens, each contributing about 8% of GPT-3’s training mix. OpenAI didn’t specify these datasets publicly, but researchers surmise that Books1 may be a collection of public domain classics (potentially Project Gutenberg) and Books2 a larger set of online books (possibly sourced from the shadow libraries). The inclusion of two book datasets ensured GPT-3 learned from long-form, well-edited text like novels and nonfiction books, complementing the more informal web text. Interestingly, OpenAI chose to up-weight the smaller Books1 corpus, sampling it multiple times (roughly 1.9 epochs) during training, whereas the larger Books2 was sampled less than once (0.43 epochs). This suggests they valued the presumably higher-quality or more classic literature in Books1 more per token than the more plentiful Books2 content.
- English Wikipedia: A 3 billion token excerpt of Wikipedia (about 3% of the mix). Wikipedia is well-structured, fact-oriented text, so including it helped GPT-3 with general knowledge and factual consistency. Despite being a small fraction of GPT-3’s data, Wikipedia’s high quality likely made it a useful component.
In sum, GPT-3’s training data was remarkably broad: internet forums, news sites, encyclopedias, and books. This diversity enabled the model’s impressive few-shot learning abilities, but it also meant GPT-3 absorbed many of the imperfections of the internet. OpenAI was relatively transparent about these sources in the GPT-3 paper, including a breakdown by token counts and even noting that higher-quality sources were oversampled to improve performance. The paper also discussed steps taken to reduce data issues (like filtering out near-duplicates and removing potentially contaminated examples of evaluation data). At this stage, transparency was still a priority – the research community knew what went into GPT-3, even if not the exact list of webpages.
GPT-4 (2023): By the time of GPT-4, OpenAI shifted to a more closed stance. GPT-4 is a multimodal model (accepting text and images) and showed significant advances in capability over GPT-3. However, OpenAI did not disclose specific details about GPT-4’s training data in the public technical report. The report explicitly states: “Given both the competitive landscape and the safety implications of large-scale models like GPT-4, this report contains no further details about the architecture (including model size), hardware, training compute, dataset construction, training method.”. In other words, unlike the earlier models, GPT-4’s creators refrained from listing its data sources or dataset sizes. Still, they have given some general hints. OpenAI has confirmed that GPT-4 was trained to predict the next token on a mix of publicly available data (e.g. internet text) and “data licensed from third-party providers”. This likely means GPT-4 used a sizable portion of the web (possibly an updated Common Crawl or similar web corpus), as well as additional curated sources that were purchased or licensed. These could include proprietary academic or news datasets, private book collections, or code repositories – though OpenAI hasn’t specified. Notably, GPT-4 is believed to have been trained on a lot of code and technical content, given its strong coding abilities. (OpenAI’s partnership with Microsoft likely enabled access to GitHub code data, and indeed GitHub’s Copilot model was a precursor in training on public code.) Observers have also inferred that GPT-4’s knowledge cutoff (September 2021 for the initial version) indicates its web crawl likely included data up to that date. Additionally, GPT-4’s vision component required image-text pairs; OpenAI has said GPT-4’s training included image data, making it a true multimodal model. All told, GPT-4’s dataset was almost certainly larger and more diverse than GPT-3’s – some reports speculated GPT-4 was trained on trillions of tokens of text, possibly incorporating around a petabyte of data including web text, books, code, and images. But without official confirmation, the exact scale remains unknown. What is clear is the shift in strategy: GPT-4’s details were kept secret, a decision that drew criticism from many in the AI community for reducing transparency. We will discuss those criticisms later. Despite the secrecy, we know GPT-4’s training data was multimodal and sourced from both open internet data and paid/licensed data, representing a wider variety of content (and languages) than any previous GPT. OpenAI’s focus had also turned to fine-tuning and alignment at scale – after the base model pre-training, GPT-4 underwent extensive refinement including reinforcement learning from human feedback (RLHF) and instruction tuning with human-written examples, which means human-curated data became an important part of its training pipeline (for alignment).
GPT-5 (2025): The latest model, GPT-5, continues the trend of massive scale and multimodality – and like GPT-4, it comes with limited official information about its training data. Launched in August 2025, GPT-5 is described as OpenAI’s “smartest, fastest, most useful model yet”, with the ability to handle text, images, and even voice inputs in one unified system. On the data front, OpenAI has revealed in its system card that GPT-5 was trained on “diverse datasets, including information that is publicly available on the internet, information that we partner with third parties to access, and information that our users or human trainers and researchers provide or generate.”. In simpler terms, GPT-5’s pre-training draw from a wide swath of the internet (websites, forums, articles), from licensed private datasets (likely large collections of text such as news archives, books or code repositories that are not freely available), and also from human-generated data provided during the training process (for example, the results of human feedback exercises, and possibly user interactions used for continual learning). The mention of “information that our users provide” suggests that OpenAI has leveraged data from ChatGPT usage and human reinforcement learning more than ever – essentially, GPT-5 has been shaped partly by conversations and prompts from real users, filtered and re-used to improve the model’s helpfulness and safety.
GPT-5’s training presumably incorporated everything that made GPT-4 powerful (vast internet text and code, multi-language content, image-text data for vision, etc.), plus additional modalities. Industry analysts believe audio and video understanding were goals for GPT-5. Indeed, GPT-5 is expected to handle full audio/video inputs, integrating OpenAI’s prior models like Whisper (speech-to-text) and possibly video analysis, which would mean training on transcripts and video-related text data to ground the model in those domains. OpenAI hasn’t confirmed specific datasets (e.g. YouTube transcripts or audio corpora), but given GPT-5’s advertised capability to understand voice and “visual perception” improvements, it’s likely that large sets of transcribed speech and possibly video descriptions were included. GPT-5 also dramatically expanded the context window (up to 400k tokens in some versions), which might indicate it was trained on longer documents (like entire books or lengthy technical papers) to learn how to handle very long inputs coherently.
One notable challenge by this generation is that the pool of high-quality text on the open internet is not infinite – GPT-3 and GPT-4 already consumed a lot of what’s readily available. AI researchers have pointed out that most high-quality public text data has already been used in training these models. For GPT-5, this meant OpenAI likely had to rely more on licensed material and synthetic data. Analysts speculate that GPT-5’s training leaned on large private text collections (for example, exclusive literary or scientific databases OpenAI could have licensed) and on model-generated data – i.e. using GPT-4 or other models to create additional training examples to fine-tune GPT-5 in specific areas. Such synthetic data generation is a known technique to bolster training where human data is scarce, and OpenAI hinted at “information that we…generate” as part of GPT-5’s data pipeline.
In terms of scale, concrete numbers haven’t been released, but GPT-5 likely involved an enormous volume of data. Some rumors suggested the training might have exceeded 1 trillion tokens or more, pushing the limits of dataset size and requiring unprecedented computing power (it was reported that Microsoft’s Azure cloud provided over 100,000 NVidia GPUs for OpenAI’s model training). The cost of training GPT-5 has been estimated in the hundreds of millions of dollars, which underscores how much data (and compute) was used – far beyond GPT-3’s 300 billion tokens or GPT-4’s rumored trillions.

Data Filtering and Quality Control: Alongside raw scale, OpenAI has iteratively improved how it filters and curates training data. GPT-5’s system card notes the use of “rigorous filtering to maintain data quality and mitigate risks”, including advanced data filtering to reduce personal information and the use of OpenAI’s Moderation API and safety classifiers to filter out harmful or sensitive content (for example, explicit sexual content involving minors, hate speech, etc.) from the training corpora. This represents a more proactive stance compared to earlier models. In GPT-3’s time, OpenAI did filter obvious spam and certain unsafe content to some extent (for instance, they excluded Wikipedia from WebText and filtered Common Crawl for quality), but the filtering was not as explicitly safety-focused as it is now. By GPT-5, OpenAI is effectively saying: we don’t just grab everything; we systematically remove sensitive personal data and extreme content from the training set to prevent the model from learning from it. This is likely a response to both ethical concerns and legal ones (like privacy regulations) – more on that later. It’s an evolution in strategy: the earliest GPTs were trained on whatever massive text could be found; now there is more careful curation, redaction of personal identifiers, and exclusion of toxic material at the dataset stage to preempt problematic behaviors.
Transparency Trends: From GPT-1 to GPT-3, OpenAI published papers detailing datasets and even the number of tokens from each source. With GPT-4 and GPT-5, detailed disclosure has been replaced by generalities. This is a significant shift in transparency that has implications for trust and research, which we will discuss in the ethics section. In summary, GPT-5’s training data is the most broad and diverse to date – spanning the internet, books, code, images, and human feedback – but the specifics are kept behind closed doors. We know it builds on everything learned from the previous models’ data and that OpenAI has put substantial effort into filtering and augmenting the data to address quality, safety, and coverage of new modalities.
2. Transparency and Data Disclosure Over Time
One clear evolution across GPT model releases has been the degree of transparency about training data. In early releases, OpenAI provided considerable detail. The research papers for GPT-2 and GPT-3 listed the composition of training datasets and even discussed their construction and filtering. For instance, the GPT-3 paper included a table breaking down exactly how many tokens came from Common Crawl, from WebText, from Books, etc., and explained how not all tokens were weighted equally in training. This allowed outsiders to scrutinize and understand what kinds of text the model had seen. It also enabled external researchers to replicate similar training mixes (as seen with open projects like EleutherAI’s Pile dataset, which was inspired by GPT-3’s data recipe).

With GPT-4, OpenAI reversed course – the GPT-4 Technical Report provided no specifics on training data beyond a one-line confirmation that both public and licensed data were used. They did not reveal the model’s size, the exact datasets, or the number of tokens. OpenAI cited the competitive landscape and safety as reasons for not disclosing these details. Essentially, they treated the training dataset as a proprietary asset. This marked a “complete 180” from the company’s earlier openness. Critics noted that this lack of transparency makes it difficult for the community to assess biases or safety issues, since nobody outside OpenAI knows what went into GPT-4. As one AI researcher pointed out, “OpenAI’s failure to share its datasets means it’s impossible to evaluate whether the training sets have specific biases… to make informed decisions about where a model should not be used, we need to know what kinds of biases are built in. OpenAI’s choices make this impossible.”. In other words, without knowing the data, we are flying blind on the model’s blind spots.
GPT-5 has followed in GPT-4’s footsteps in terms of secrecy. OpenAI’s public communications about GPT-5’s training data have been high-level and non-quantitative. We know categories of sources (internet, licensed, human-provided), but not which specific datasets or in what proportions. The GPT-5 system card and introduction blog focus more on model capabilities and safety improvements than on how it was trained. This continued opacity has been met with calls for more transparency. Some argue that as AI systems become more powerful and widely deployed, the need for transparency increases – to ensure accountability – and that OpenAI’s pivot to closed practices is concerning. Even UNESCO’s 2024 report on AI biases highlighted that open-source models (where data is known) allow the research community to collaborate on mitigating biases, whereas closed models like GPT-4 or Google’s Gemini make it harder to address these issues due to lack of insight into their training data.
It’s worth noting that OpenAI’s shift is partly motivated by competitive advantage. The specific makeup of GPT-4/GPT-5’s training corpus (and the tricks to cleaning it) might be seen as giving them an edge over rivals. Additionally, there’s a safety argument: if the model has dangerous capabilities, perhaps details could be misused by bad actors or accelerate misuse. OpenAI’s CEO Sam Altman has said that releasing too much info might aid “competitive and safety” challenges, and OpenAI’s chief scientist Ilya Sutskever described the secrecy as a necessary “maturation of the field,” given how hard it was to develop GPT-4 and how many companies are racing to build similar models. Nonetheless, the lack of transparency marks a turning point from the ethos of OpenAI’s founding (when it was a nonprofit vowing to openly share research). This has become an ethical issue in itself, as we’ll explore next – because without transparency, it’s harder to evaluate and mitigate biases, harder for outsiders to trust the model, and difficult for society to have informed discussions about what these models have ingested.
3. Ethical Concerns and Controversies in Training Data
The choices of training data for GPT models have profound ethical implications. The datasets not only impart factual knowledge and linguistic ability, but also embed the values, biases, and blind spots of their source material. As models have grown more powerful (GPT-3, GPT-4, GPT-5), a number of ethical concerns and public debates have emerged around their training data:
3.1 Bias and Stereotypes in the Data
One major issue is representational bias: large language models can pick up and even amplify biases present in their training text, leading to outputs that reinforce harmful stereotypes about race, gender, religion, and other groups. Because these models learn from vast swaths of human-written text (much of it from the internet), they inevitably learn the prejudices and imbalances present in society and online content.
For example, researchers have documented that GPT-family models sometimes produce sexist or racist completions even from seemingly neutral prompts. A 2024 UNESCO study found “worrying tendencies” in generative AI outputs, including GPT-2 and GPT-3.5, such as associating women with domestic and family roles far more often than men, and linking male identities with careers and leadership. In generated stories, female characters were frequently portrayed in undervalued roles (e.g. “cook”, “prostitute”), while male characters were given more diverse, high-status professions (“engineer”, “doctor”). The study also noted instances of homophobic and racial stereotyping in model outputs. These biases mirror patterns in the training data (for instance, a disproportionate share of literature and web text might depict women in certain ways), but the model can learn and regurgitate these patterns without context or correction.
Another stark example comes from religious bias: GPT-3 was shown to have a significant anti-Muslim bias in its completions. In a 2021 study by Abid et al., researchers prompted GPT-3 with the phrase “Two Muslims walk into a…” and found that 66% of the time the model’s completion referenced violence (e.g. “walk into a synagogue with axes and a bomb” or “…and start shooting”). By contrast, when they used other religions in the prompt (“Two Christians…” or “Two Buddhists…”), violent references appeared far less often (usually under 10%). GPT-3 would even finish analogies like “Muslim is to ___” with “terrorist” 25% of the time. These outputs are alarming – they indicate the model associated the concept “Muslim” with violence and extremism. This likely stems from the training data: GPT-3 ingested millions of pages of internet text, which undoubtedly included Islamophobic content and disproportionate media coverage of terrorism. Without explicit filtering or bias correction in the data, the model internalized those patterns. The researchers labeled this a “severe bias” with real potential for harm (imagine an AI system summarizing news and consistently portraying Muslims negatively, or a user asking a question and getting a subtly prejudiced answer).
While OpenAI and others have tried to mitigate such biases in later models (mostly through fine-tuning and alignment techniques), the root of the issue lies in the training data. GPT-4 and GPT-5 were trained on even larger corpora that likely still contain biased representations of marginalized groups. OpenAI’s alignment training (RLHF) aims to have the model refuse or moderate overtly toxic outputs, which helps reduce the blatant hate speech. GPT-4 and GPT-5 are certainly more filtered in their output by design than GPT-3 was. However, research suggests that covert biases can persist. A 2024 Stanford study found that even after safety fine-tuning, models can still exhibit “outdated stereotypes” and racist associations, just in more subtle ways. For instance, large models might produce lower quality answers or less helpful responses for inputs written in African American Vernacular English (AAVE) as opposed to “standard” English, effectively marginalizing that dialect. The Stanford researchers noted that current models (as of 2024) still surface extreme racial stereotypes dating from the pre-Civil Rights era in certain responses. In other words, biases from old books or historical texts in the training set can show up unless actively corrected.

These findings have led to public debate and critique. The now-famous paper “On the Dangers of Stochastic Parrots” (Bender et al., 2021) argued that blindly scaling up LLMs can result in models that “encode more bias against identities marginalized along more than one axis” and regurgitate harmful content. The authors emphasized that LLMs are “stochastic parrots” – they don’t understand meaning; they just remix and repeat patterns in data. If the data is skewed or contains prejudices, the model will reflect that. They warned of risks like “unknown dangerous biases” and the potential to produce toxic or misleading outputs at scale. This critique gained notoriety not only for its content but also because one of its authors (Timnit Gebru at Google) was fired after internal controversy about the paper – highlighting the tension in big tech around acknowledging these issues.
For GPT-5, OpenAI claims to have invested in safety training to reduce problematic outputs. They introduced new techniques like “safe completions” to have the model give helpful but safe answers instead of just hard refusals or unsafe content. They also state GPT-5 is less likely to produce disinformation or hate speech compared to prior models, and they did internal red-teaming for fairness issues. Moreover, as mentioned, they filtered certain content out of the training data (e.g. explicit sexual content, likely also hate content). These measures likely mitigate the most egregious problems. Yet, subtle representational biases (like gender stereotypes in occupations, or associations between certain ethnicities and negative traits) can be very hard to eliminate entirely, especially if they permeate the vast training data. The UNESCO report noted that even closed models like GPT-4/GPT-3.5, which undergo more post-training alignment, still showed gender biases in their outputs.
In summary, the ethical concern is that without careful curation, LLM training data encodes the prejudices of society, and the model will unknowingly reproduce or even amplify them. This has led to calls for more balanced and inclusive datasets, documentation of dataset composition, and bias testing for models. Some researchers advocate “datasheets for datasets” and deliberate inclusion of underrepresented viewpoints in training corpora (or conversely, exclusion of problematic sources) to prevent skew. OpenAI and others are actively researching bias mitigation, but it remains a cat-and-mouse game: as models get more complex, understanding and correcting their biases becomes more challenging, especially if the training data is not fully transparent.
3.2 Privacy and Copyright Concerns
Another controversy centers on the content legality and privacy of what goes into these training sets. By scraping the web and other sources en masse, the GPT models have inevitably ingested a lot of material that is copyrighted or personal, raising questions of permission and fair use.
Copyright and Data Ownership: GPT models like GPT-3, 4, 5 are trained on billions of sentences from books, news, websites, etc. – many of which are under copyright. For a long time, this was a grey area given that the training process doesn’t reproduce texts verbatim (at least not intentionally), and companies treated web scraping as fair game. However, as the impact of these models has grown, authors and content creators have pushed back. In mid-2023 and 2024, a series of lawsuits were filed against OpenAI (and other AI firms) by groups of authors and publishers. These lawsuits allege that OpenAI unlawfully used copyrighted works (novels, articles, etc.) without consent or compensation to train GPT models, which is a form of mass copyright infringement. By 2025, at least a dozen such U.S. cases had been consolidated in a New York court – involving prominent writers like George R.R. Martin, John Grisham, Jodi Picoult, and organizations like The New York Times. The plaintiffs argue that their books and articles were taken (often via web scraping or digital libraries) to enrich AI models that are now commercial products, essentially “theft of millions of … works” in the words of one attorney.
OpenAI’s stance is that training on publicly accessible text is fair use under U.S. copyright law. They contend that the model does not store or output large verbatim chunks of those works by default, and that using a broad corpus of text to learn linguistic patterns is a transformative, innovative use. An OpenAI spokesperson responded to the litigation saying: “Our models are trained on publicly available data, grounded in fair use, and supportive of innovation.”. This is a core of the debate: is scraping the internet (or digitizing books) to train an AI akin to a human reading those texts and learning from them (which would be fair use and not infringement)? Or is it a reproducing of the text in a different form that competes with the original, thus infringing? The legal system is now grappling with these questions, and the GPT-5 era might force new precedents. Notably, some news organizations have also sued; for example, The New York Times is reported to have taken action against OpenAI for using its articles in training without license.

For GPT-5, it’s likely that even more copyrighted material ended up in the mix, especially if OpenAI licensed some datasets. If they licensed, say, a big corpus of contemporary fiction or scientific papers, then those might be legally acquired. But if not, GPT-5’s web data could include many texts that rights holders object to being used. This controversy ties back to transparency: because OpenAI won’t disclose exactly what data was used, authors find it difficult to know for sure if their works were included – although some clues emerge when the model can recite lines from books, etc. The lawsuits have led to calls for an “opt-out” or compensation system, where content creators could exclude their sites from scraping or get paid if their data helps train models. OpenAI has recently allowed website owners to block its GPTBot crawler from scraping content (via a robots.txt rule), implicitly acknowledging the concern. The outcome of these legal challenges will be pivotal for the future of AI dataset building.
Personal Data and Privacy: Alongside copyrighted text, web scraping can vacuum up personal information – like private emails that leaked online, social media posts, forum discussions, and so on. Early GPT models almost certainly ingested some personal data that was available on the internet. This raises privacy issues: a model might memorize someone’s phone number, address, or sensitive details from a public database, and then reveal it in response to a query. In fact, researchers have shown that large language models can, in rare cases, spit out verbatim strings from training data (for example, a chunk of software code with an email address, or a direct quote from a private blog) – this is called training data extraction. Privacy regulators have taken note. In 2023, Italy’s data protection authority temporarily banned ChatGPT over concerns that it violated GDPR (European privacy law) by processing personal data unlawfully and failing to inform users. OpenAI responded by adding user controls and clarifications, but the general issue remains: these models were not trained with individual consent, and some of that data might be personal or sensitive.
OpenAI’s approach in GPT-5 reflects an attempt to address these privacy concerns at the data level. As mentioned, the data pipeline for GPT-5 included “advanced filtering processes to reduce personal information from training data.”. This likely means they tried to scrub things like government ID numbers, private contact info, or other identifying details from the corpus. They also use their Moderation API to filter out content that violates privacy or could be harmful. This is a positive step, because it reduces the chance GPT-5 will memorize and regurgitate someone’s private details. Nonetheless, privacy advocates argue that individuals should have a say in whether any of their data (even non-sensitive posts or writings) are used in AI training. The concept of “data dignity” suggests people’s digital exhaust has value and should not be taken without permission. We’re likely to see more debate and possibly regulation on this front – for instance, discussions about a “right to be excluded” from AI training sets, similar to the right to deletion in privacy law.
Model Usage of User Data: Another facet is that once deployed, models like ChatGPT continue to learn from user interactions. By default, OpenAI has used ChatGPT conversations (the ones that users input) to further fine-tune and improve the model, unless users opt out. This means our prompts and chats become part of the model’s ongoing training data. A Stanford study in late 2025 highlighted that leading AI companies, including OpenAI, were indeed “pulling user conversations for training”, which poses privacy risks if not properly handled. OpenAI has since provided options for users to turn off chat history (to exclude those chats from training) and promises not to use data from its enterprise customers for training by default. But this aspect of data collection has also been controversial, because users often do not realize that what they tell a chatbot could be seen by human reviewers or used to refine the model.
3.3 Accountability and the Debate on Openness
The above concerns (bias, copyright, privacy) all feed into a larger debate about AI accountability. If a model outputs something harmful or incorrect, knowing the training data can help diagnose why. Without transparency, it’s hard for outsiders to trust that the model isn’t, for example, primarily trained on highly partisan or dubious sources. The tension is between proprietary advantage and public interest. Many researchers call for dataset transparency as a basic requirement for AI ethics – akin to requiring a nutrition label on what went into the model. OpenAI’s move away from that has been criticized by figures like Emily M. Bender, who tweeted that the secrecy was unsurprising but dangerous, saying OpenAI was “willfully ignoring the most basic risk mitigation strategies” by not disclosing details. The company counters that it remains committed to safety and that it balances openness with the realities of competition and misuse potential.

There is also an argument that open models (with open training data) allow the community to identify and fix biases more readily. UNESCO’s analysis explicitly notes that while open-source LLMs (like Meta’s LLaMA 2 or the older GPT-2) showed more bias in raw output, their “open and transparent nature” is an advantage because researchers worldwide can collaborate to mitigate these biases, something not possible with closed models like GPT-3.5/4 where the data and weights are proprietary. In other words, openness might lead to better outcomes in the long run, even if the open models start out more biased, because the transparency enables accountability and improvement. This is a key point in public debates: should foundational models be treated as infrastructure that is transparent and scrutinizable? Or are they intellectual property to be guarded?
Another ethical aspect is environmental impact – training on gigantic datasets consumes huge energy – though this is somewhat tangential to data content. The “Stochastic Parrots” paper also raised the issue of the carbon footprint of training ever larger models. Some argue that endlessly scraping more data and scaling up is unsustainable. Companies like OpenAI have started to look into data efficiency (e.g., using synthetic data or better algorithms) so that we don’t need to double dataset size for each new model.
Finally, misinformation and content quality in training data is a concern: GPT-5’s knowledge is only as good as its sources. If the training set contains a lot of conspiracy theories or false information (as parts of the internet do), the model might internalize some of that. Fine-tuning and retrieval techniques are used to correct factual errors, but the opacity of GPT-4/5’s data makes it hard to assess how much misinformation might be embedded. This has prompted calls for using more vetted sources or at least letting independent auditors evaluate the dataset quality.
In conclusion, the journey from GPT-1 to GPT-5 shows not just technological progress, but also a growing awareness of the ethical dimensions of training data. Issues of bias, fairness, consent, and transparency have become central to the discourse around AI. OpenAI has adapted some practices (like filtering data and aligning model behavior) to address these, but at the same time has become less transparent about the data itself, raising questions in the AI ethics community. Going forward, finding the right balance between leveraging vast data and respecting ethical and legal norms will be crucial. The public debates and critiques – from Stochastic Parrots to author lawsuits – are shaping how the next generations of AI will be trained. GPT-5’s development shows that what data we train on is just as important as how many parameters or GPUs we use. The composition of training datasets profoundly influences a model’s capabilities and flaws, and thus remains a hot-button topic in both AI research and society at large.
4. Bringing AI Into the Real World – Responsibly
While the training of large language models like GPT-5 raises valid questions about data ethics, transparency, and bias, it also opens the door to immense possibilities. The key lies in applying these tools thoughtfully, with a deep understanding of both their power and their limitations. At TTMS, we help businesses harness AI in ways that are not only effective, but also responsible — whether it’s through intelligent automation, custom GPT integrations, or AI-powered decision support systems.
If you’re exploring how AI can serve your organization — without compromising trust, fairness, or compliance — our team is here to help. Get in touch to start the conversation.
5. What’s New in GPT‑5.1? Training Methods Refined, Data Privacy Strengthened
GPT‑5.1 did not introduce a revolution in terms of training data-it relies on the same data foundation as GPT‑5. The data sources remain similar: massive open internet datasets (including web text, scientific publications, and code), multimodal data (text paired with images, audio, or video), and an expanded pool of synthetic data generated by earlier models. GPT‑5 already employed such a mix-training began with curated internet content, followed by more complex tasks (some synthetically generated by GPT‑4), and finally fine-tuned using expert-level questions to enhance advanced reasoning capabilities.
GPT‑5.1 did not introduce new categories of data, but it improved model tuning methods: OpenAI adjusted the model based on user feedback, resulting in GPT‑5.1 having a notably more natural, “warmer” conversational tone and better adherence to instructions. At the same time, its privacy approach remained strict-user data (especially from enterprise ChatGPT customers) is not included in the training set without consent and undergoes anonymization.
The entire training pipeline was further enhanced with improved filtering and quality control: harmful content (e.g., hate speech, pornography, personal data, spam) is removed, and the model is trained to avoid revealing sensitive information. Official materials confirm that the changes in GPT‑5.1 mainly concern model architecture and fine-tuning-not new training data
FAQ
What data sources were used to train GPT-5, and how is it different from earlier GPT models’ data?
GPT-5 was trained on a mixture of internet text, licensed third-party data, and human-generated content. This is similar to GPT-4, but GPT-5’s dataset is even more diverse and multimodal. For example, GPT-5 can handle images and voice, implying it saw image-text pairs and possibly audio transcripts during training (whereas GPT-3 was text-only). Earlier GPTs had more specific data profiles: GPT-2 used 40 GB of web pages (WebText); GPT-3 combined filtered Common Crawl, Reddit links, books, and Wikipedia. GPT-4 and GPT-5 likely included all those plus more code and domain-specific data. The biggest difference is transparency – OpenAI hasn’t fully disclosed GPT-5’s sources, unlike the detailed breakdown provided for GPT-3. We do know GPT-5’s team put heavy emphasis on filtering the data (to remove personal info and toxic content), more so than in earlier models.
Did OpenAI use copyrighted or private data to train GPT-5?
OpenAI states that GPT-5 was trained on publicly available information and some data from partner providers. This almost certainly includes copyrighted works that were available online (e.g. articles, books, code) – a practice they argue is covered by fair use. OpenAI likely also licensed certain datasets (which could include copyrighted text acquired with permission). As for private data: the training process might have incidentally ingested personal data that was on the internet, but OpenAI says it filtered out a lot of personal identifying information in GPT-5’s pipeline. In response to privacy concerns and regulations, OpenAI has also allowed people to opt out their website content from being scraped. So while GPT-5 did learn from vast amounts of online text (some of which is copyrighted or personal), OpenAI took more steps to sanitize the data. Ongoing lawsuits by authors claim that using their writings for training was unlawful, so this is an unresolved issue being debated in courts.
How do biases in training data affect GPT-5’s outputs?
Biases present in the training data can manifest in GPT-5’s responses. If certain stereotypes or imbalances are common in the text the model read, the model may inadvertently reproduce them. For instance, if the data associated leadership roles mostly with men and domestic roles with women, the model might reflect those associations in generated content. OpenAI has tried to mitigate this: they filtered overt hate or extreme content from the data and fine-tuned GPT-5 with human feedback to avoid toxic or biased outputs. As a result, GPT-5 is less likely to produce blatantly sexist or racist statements compared to an unfiltered model. However, subtle biases can still occur – for example, GPT-5 might unconsciously use a more masculine persona by default or make assumptions about someone’s background in certain contexts. Bias mitigation is imperfect, so while GPT-5 is safer and more “politically correct” than its predecessors, users and researchers have noted that some stereotypes (gender, ethnic, etc.) can slip through in its answers. Ongoing work aims to further reduce these biases by improving training data diversity and better alignment techniques.
Why was there controversy over OpenAI not disclosing GPT-4 and GPT-5’s training data?
The controversy stems from concerns about transparency and accountability. With GPT-3, OpenAI openly shared what data was used, which allowed the community to understand the model’s strengths and weaknesses. For GPT-4 and GPT-5, OpenAI decided not to reveal details like the exact dataset composition or size. They cited competitive pressure and safety as reasons. Critics argue that this secrecy makes it impossible to assess biases or potential harms in the model. For example, if we don’t know whether a model’s data heavily came from one region or excluded certain viewpoints, we can’t fully trust its neutrality. Researchers also worry that lack of disclosure breaks from the tradition of open scientific inquiry (especially ironic given OpenAI’s original mission of openness). The issue gained attention when the GPT-4 Technical Report explicitly provided no info on training data, leading some AI ethicists to say the model was not “open” in any meaningful way. In summary, the controversy is about whether the public has a right to know what went into these powerful AI systems, versus OpenAI’s stance that keeping it secret is necessary in today’s AI race.
What measures are taken to ensure the training data is safe and high-quality for GPT-5?
OpenAI implemented several measures to improve data quality and safety for GPT-5. First, they performed rigorous filtering of the raw data: removing duplicate content, eliminating obvious spam or malware text, and excluding categories of harmful content. They used automated classifiers (including their Moderation API) to filter out hate speech, extreme profanity, sexually explicit material involving minors, and other disallowed content from the training corpus. They also attempted to strip personal identifying information to address privacy concerns. Second, OpenAI enriched the training mix with what they consider high-quality data – for instance, well-curated text from books or reliable journals – and gave such data higher weight during training (a practice already used in GPT-3 to favor quality over quantity). Third, after the initial training, they fine-tuned GPT-5 with human feedback: this doesn’t change the core data, but it teaches the model to avoid producing unsafe or incorrect outputs even if the raw training data had such examples. Lastly, OpenAI had external experts “red team” the model, testing it for flaws or biases, and if those were found, they could adjust the data or filters and retrain iterations of the model. All these steps are meant to ensure GPT-5 learns from the best of the data and not the worst. Of course, it’s impossible to make the data 100% safe – GPT-5 still learned from the messy real world, but compared to earlier GPT versions, much more effort went into dataset curation and safety guardrails.






